
プレゼン直前にClaudeが動かない、商談の議事録をAIに要約させようとしたのに返事が返ってこない、月末の資料を仕上げているさなかに画面が真っ白——。
10人規模のマーケティング会社で役員をしている方から、先月こんな相談を受けました。「大事な提案書の仕上げをClaudeにやらせていたら、突然エラーが出て固まった。私のパソコンが壊れたのかと思って1時間近くパニックになって、結局その日の提出が翌朝にずれ込んだ」。別の士業の方は「Claude Codeで請求書の集計をさせていたら途中で止まって、どこまで処理が進んだのか分からず、結局自分で最初からやり直した」と話していました。
こういう場面で非エンジニアが最初につまずくのは、「私のPCの問題なのか、それとも Claude 側の障害なのか」の切り分けです。ここで迷うと、ITに詳しい人を探して回るうちに30分〜1時間が溶けます。
この記事は、Claudeが急に使えなくなったときに3分で切り分け、30分以内に仕事を再開するための即応ガイドです。2026年7月時点の最新情報に合わせて更新しています。読み終わると次の3つが手に入ります。①障害か自分側かを判別する3分フロー、②新しくなった公式ステータスページ(status.claude.com)の読み方、③障害中でも仕事を進められる5つの代替手段。
2026年6月の重要な変更点: これまで障害確認の定番だった
status.anthropic.comは、現在アクセスすると自動的にstatus.claude.comに転送されます(302リダイレクト)。古いブックマークのままでも飛べますが、新しいURLを覚えておくと確実です。
ここから先は本論です
まず結論——Claudeが止まったら、この順番で動く
細かい解説の前に、結論を先に出します。Claudeが動かなくなったら、次の順番で動けば大丈夫です。
- 3分で切り分ける(再読み込み → シークレットウィンドウ → スマホのモバイル回線)。これで直れば、そもそもAnthropic側の障害ではありません。
- status.claude.com を見る。緑(Operational)以外の表示や、進行中のIncidentがあればAnthropic側の障害です。
- 代替手段に切り替える(動いている機能・モデルに寄せる、別AIに一時退避、手書きで先行)。
そして覚えておいてほしい一番大事な事実は、Claude障害のほとんどは数分〜数十分で復旧するということです。直近の障害履歴を見ても、2026年7月4日と7月6日に記録された計4件のエラー増加は、いずれも11分〜1時間半ほどで「Resolved(解決済み)」になっています。焦らず、この記事の手順どおりに動けば、非エンジニアでも障害を怖がらずに済みます。
Claude 障害の3つのパターン——まず全体像を頭に入れる
最初に知っておいてほしいのは、Claudeの障害は全部同じではないということです。大きく分けて3パターンあります。これを知っておくだけで「あ、いまは2パターン目だから、こっちの代替で動ける」と冷静に判断できます。
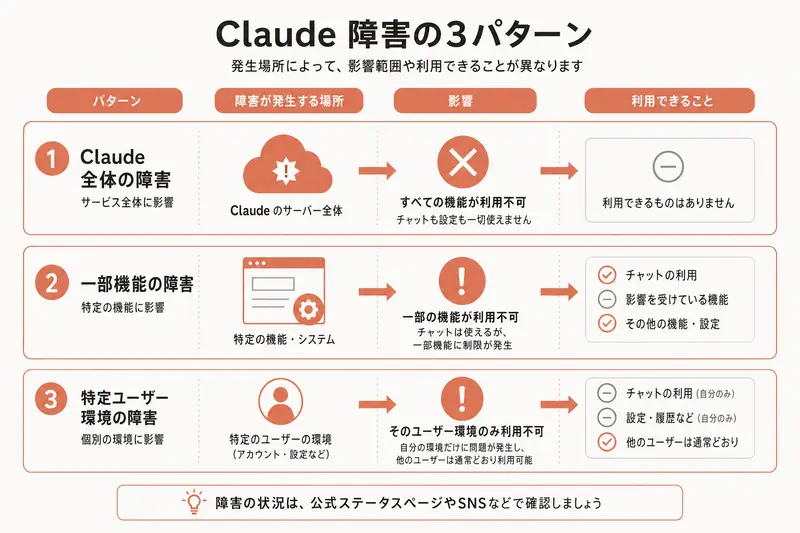
パターン1: 全面停止(claude.ai も Claude Code も API も全滅)
最も分かりやすい障害です。ブラウザの claude.ai を開いてもエラー、Claude Code を起動してもAPIに繋がらない、という状態になります。Anthropic側のインフラ(サーバーやネットワーク)で大きな障害が起きているケースです。
実例として、2026年6月5日には claude.ai・Claude API・Claude Code・Claude Cowork を含む広い範囲でエラー率が上昇する大規模障害が起きました(日本時間では深夜帯、UTC 15:08頃の発生)。このときは全モデルの成功率が通常水準に戻るまで、復旧に約2時間かかっています。とはいえ、こうした全面停止は頻繁ではなく、数ヶ月に1回あるかどうかというペースです。
パターン2: 一部機能・モデル停止(特定のモデルやサービスだけ止まる)
「claude.ai のチャットは動くのに、Claude Code だけ動かない」「Sonnetモデルは使えるが Opus だけタイムアウトする」といった、部分的な障害です。
非エンジニアにとって一番困惑するのはこのパターンです。ブラウザの claude.ai だけは普通に動いているのに、Claude Codeでだけエラーが出るという状況が起きやすく、「自分のCode側の設定がおかしいのでは」と疑ってしまいがちです。
2026年6月の公式ステータスを見ると、実はこのパターンが圧倒的に多いことが分かります。7月上旬だけでも、7月4日の朝(日本時間6:55〜7:06)に特定モデルで11分間のエラー増加、続く8:42〜9:20に複数モデルへ広がるエラー増加、7月6日の夕方(日本時間16:36〜18:13)にも複数モデルのエラー増加が記録されていますが、いずれもその日のうちにResolvedとなっており、このパターン2が引き続き最多です。「Elevated errors on Claude Opus 4.8(Opus 4.8でエラー増加)」のように、特定のモデル1つだけが一時的に不調になるケースが繰り返し記録されています。多くは数分〜1時間ほどで解消されます。
パターン3: 速度低下・エラー率上昇(動くけど遅い・途中で切れる)
完全に止まってはいないのですが、返事が極端に遅い、長い応答の途中で切れる、たまにタイムアウトになるという症状です。
これが一番よくある障害です。世界中で一気にClaudeの利用が増えた時間帯や、Anthropicが新しいモデルをリリースした直後などに起きやすく、ほとんどの場合は数分〜数十分で自然回復します。実は「ちょっと遅いな」と感じる時間帯の多くがこのパターンです。
この記事では、3つのパターンすべてを想定した即応方法を解説します。
最初の3分——「自分側か Claude 側か」を切り分ける
Claudeが動かないと感じたら、まず3分で切り分けます。ここで焦らず順番に確認すれば、IT担当者を呼ばなくても自己判断できます。
症状の呼び方はどれでも手順は同じ——不具合・動かない・応答しない・調子が悪い
Claudeが動かない、送信しても応答しない、ボタンを押しても反応しない、今日はなんだか不具合っぽい。呼び方は人それぞれですが、切り分けの手順はすべて同じです。1つだけ意識しておくと速いのは、返事がまったく返ってこない(動かない・応答しない)のか、返ってくるけれど遅い・途中で切れる(調子が悪い)のかという違いです。前者は障害かログイン・ブラウザまわり、後者はパターン3の速度低下(過負荷)が濃厚です。それでは順番に確認していきます。
ステップ1: ブラウザを再読み込みする
まずは単純に、ブラウザの再読み込みボタン(WindowsならCtrl+R、MacならCmd+R)を押します。claude.ai では画面が一瞬固まっただけで、再読み込みで回復するケースが珍しくありません。これで直れば、そもそも障害ですらなかったということです。
ステップ2: シークレットウィンドウで開く
Chromeなら右上の「︙」→「新しいシークレットウィンドウ」、Edgeなら「新しい InPrivate ウィンドウ」で開きます。そこで claude.ai にアクセスしてログインし直してください。
ここで動けば、元のブラウザの拡張機能やキャッシュが悪さをしている可能性が高く、Claude側の障害ではありません。元のブラウザでキャッシュをクリアすれば直ります。Chrome拡張のClaude機能を使っている方は、Claude を Chrome で使う方法 も合わせて見ておくと、拡張側のトラブルと本体障害を切り分けやすくなります。
ステップ3: スマートフォンのモバイル回線で開く
会社のWi-Fiや自宅の回線に問題がある可能性も排除します。スマートフォンのWi-Fiを切り、モバイル回線(4G/5G)にして、ブラウザから claude.ai にアクセスしてみてください。
スマホからは動くのにパソコンからだけ動かないなら、オフィスのネットワーク側に問題がある可能性が高いです。社内のルーターやファイアウォールで claude.ai がブロックされている、プロキシの設定が変わった、VPNが落ちている、などが典型です。この場合はIT担当者にエスカレーションします。
ステップ4: 公式ステータスページを見る
ここまで試してもダメなら、ほぼ Claude 側の障害です。念のため公式ステータスページで確認します。
- 確認先URL: status.claude.com(旧 status.anthropic.com からも自動転送されます)
- 補助情報: Downdetector など第三者の障害検知サイトでも、同時刻に報告が急増していれば全体障害の裏付けになります
- 英語が苦手な方向け: 当サイトのClaude稼働状況ページ(/status)なら、同じ公式データを日本語でリアルタイム表示します
この3分ステップで90%以上のケースは原因が特定できます。残りの数%は社内ネットワークの深い設定問題なので、これはIT担当者の領域です。ステータスページの基本的な見方と自己診断の手順は、別記事 Claude の稼働状況を確認する方法 で図解付きにまとめていますので、合わせて読むとより確実です。
status.claude.com の読み方——英語ページでも怖くない
Claude の公式ステータスページは英語ですが、構造はシンプルです。見るべき場所は3つだけ覚えておけば十分です。2026年7月時点でも、ページのURLが status.claude.com です(古い status.anthropic.com にアクセスしても自動的にこちらへ転送されます)。
見るべき場所1: 上部の「All Systems Operational」の表示
ページ最上部に緑色のバーがあり、「All Systems Operational(全システム正常)」と表示されていれば、Anthropic側は正常稼働中です。一部障害なら黄色、大規模障害なら赤に変わります。
見るべき場所2: サービス別の稼働状況一覧(2026年7月時点も6つ)
下にスクロールすると、サービス別の稼働状況が並んでいます。2026年7月時点で監視対象は次の6つです。
| サービス名 | 内容 | 非エンジニアの関係度 |
|---|---|---|
| claude.ai | ブラウザ版のチャット | 高い |
| Claude Console(platform.claude.com) | APIキー管理・課金画面 | API利用者のみ |
| Claude API(api.anthropic.com) | Claude Code が裏で使うAPI | Code利用者は高い |
| Claude Code | ターミナルで動くAIエージェント | 高い |
| Claude Cowork | 文書作成・要約・分析のWebアプリ | 高い |
| Claude for Government | 行政機関向け | 該当者のみ |
たとえば claude.ai が緑でClaude Codeが赤なら、ブラウザのチャットは使えるがClaude Codeは止まっている、と判断できます。これが前章のパターン2にあたります。各サービスには直近90日の稼働率(おおむね99%台。2026年7月12日の実測ではclaude.ai 99.43%、Claude API 99.57%、Claude Code 99.51%、Claude Cowork 99.58%)も表示され、安定性の目安になります。
見るべき場所3: Recent Incidents(最近の障害)セクション
ページ中段に「Past Incidents」「Recent Incidents」という欄があり、進行中の障害と直近の障害履歴が並んでいます。進行中の障害は次の4つの状態で表示されます。
- Investigating(調査中): 障害が報告されたばかり。原因特定中
- Identified(原因特定): 原因が分かり、対処中
- Monitoring(経過観察): 対処が終わり、復旧を確認中
- Resolved(解決済み): 完全復旧
2026年6月〜7月の実際のログを見ると、「Elevated errors on Claude Opus 4.8(Opus 4.8でエラー増加)」のようなモデル単位の不具合が多く、その大半が数分〜1時間でResolvedに到達しています。いまInvestigatingでも、過去の傾向からすれば長くても1〜2時間以内に戻ると見込んで、その間の仕事の段取りを組み直せます。
直近の実例では、2026年7月7日〜10日の4日間に、Opus 4.8 や Sonnet 5 など特定モデルのエラー増加、MCPサーバー(ClaudeにNotionやSlackなど外部ツールを繋ぐ拡張機能)の認証の不具合、Claude Code on the web の速度低下が計9件記録されましたが、すべて当日中にResolvedになっています。
障害通知を自動で受け取る(Subscribe to updates)
ページ上部の「Subscribe to updates」から、障害の発生・更新・復旧を自動で受け取れます。2026年7月時点でも、メール・SMS・Slack・Microsoft Teams・Webhook・RSS(Atom)の6つの方法に対応しています。普段Slackを使っているチームなら、専用チャンネルに障害情報を自動投稿させておくと、誰かが手動で監視する必要がなくなります。
Claude障害をリアルタイムで確認する方法(X・旧Twitterの日本語検索)
公式ステータスページは英語ですが、日本のX(旧Twitter)で「Claude 障害」「Claude 不具合」「Claude 落ちてる」などで検索すると、日本人ユーザーがリアルタイムで「自分も同じ症状」と投稿していることがよくあります。これで「全員巻き込まれているから Anthropic 障害だな」と即座に判断できる場合が多いです。あくまで一次情報は status.claude.com 側ですが、体感的な速報性ではSNS検索が役立ちます。
障害中でも仕事を止めない5つの代替手段
障害が確定したら、次は「じゃあどうやって今日の仕事を進めるか」です。Claudeが使えない30分〜2時間を、ただ待つのはもったいない時間です。5つの手があります。
代替手段1: 直近のチャット履歴を活用する
claude.ai は、過去のチャット履歴をブラウザに表示するときに新しい通信をしないことがあります。つまり、障害中でも過去のやり取りは読めるケースが多いのです。
さっきまで書いていた下書き、整理してくれた箇条書き、要約してもらった長文——これらを履歴から選択コピーして、Word やメモ帳に貼り付ければ、そのまま続きを自分で書けます。Claudeが途中まで作ってくれたものを無駄にしないことが重要です。
代替手段2: claude.ai と Claude Code のどちらかだけ動いているか確認
前章のパターン2(一部機能停止)のとき、片方だけ動いていることがよくあります。「claude.ai で下書きを作って、それをローカルのファイルに貼るだけ」「Claude Code でファイル操作だけしてclaude.aiで文章生成する」といった形で、動いているほうに一時的に寄せるのが有効です。
Claude Codeが止まってclaude.aiだけ動いているときは、ブラウザのclaude.aiに今日やりたかったタスクをテキストで貼り付けて、「この内容でスクリプトを書いてほしい」と頼むだけで、ある程度の代替になります。
代替手段3: モデルを切り替える
特定のモデルだけ落ちるのは、2026年6月の障害でも最も多いパターンです。たとえば6月5日の障害では、Opus 4.6 は約17分で復旧したのに、Opus 4.8 が通常水準に戻るまでは1時間50分ほどかかった、というようにモデルごとに復旧タイミングが大きくバラついた実例があります。
つまり、「いつものOpus 4.8が落ちていても、Sonnet 4.6やHaiku 4.5なら動く」ということが起こり得ます。claude.aiならモデル選択のドロップダウンで、Claude Codeなら /model コマンドで切り替えられます。品質より復旧優先と割り切って、一段下のモデルに切り替えるだけで作業を継続できることが多いです。それぞれのモデルの違いは Claude Opus とは何か で解説しています。
代替手段4: 別の対話型AIでピンチヒッター
30分以上続きそうな障害のときは、他のAIに一時的に逃がします。現実的な選択肢は次の3つです。
- ChatGPT(OpenAI): 月20ドル程度のPlanを1つ保険として持っておくと安心
- Gemini(Google): Google Workspaceを使っていれば追加契約不要で使える場合がある
- Microsoft Copilot(Microsoft 365のサブスク内): 普段Wordを使う会社なら無料追加枠で使える
普段からClaudeをメインで使っていて、片方だけサブ契約を持っておくのが、業務影響を最小化するコツです。月数千円の保険と割り切る考え方です。ClaudeとChatGPTの使い分けで迷う方は Claude と ChatGPT の違い も参考にしてください。
代替手段5: 手書きとテンプレートで先に進める
AIが全部止まっても、思考整理は紙と手書きでできるという事実を忘れないでください。提案書の骨子を手書きで書き出しておき、Claudeが復旧したら清書だけ任せる。議事録のメモを箇条書きで手で取っておき、後で要約をお願いする。メール下書きも、よく使う言い回しのテンプレートを自分の辞書登録しておけば、AIなしでも一定品質の文面が作れます。
障害中に「ただ待つ」のではなく、復旧後にClaudeが一瞬で仕上げられる状態まで手で進めておくのが、最も賢い時間の使い方です。
障害耐性のあるワークフロー——明日から仕込む5つの習慣
ここまでは「いま障害が起きているとき」の話でした。ここからは、二度とパニックにならないための日常の仕込みの話です。2026年6月〜7月のように障害がやや立て込む時期(Opus系モデルで短時間のエラー増加が繰り返される時期)もあるので、この備えは効いてきます。
習慣1: 重要な締切の24時間前ルール
「明日の10時にプレゼン」「金曜の17時に提出」のような重要な締切は、Claudeへの依存を締切の24時間前までに終わらせるルールを自分に課してください。これだけで、直前障害で慌てることが激減します。
金曜17時提出なら、木曜17時までにClaudeに生成させる作業は完了させる。あとの24時間は人間の目でのチェック、自分の加筆修正、関係者への事前共有にあてます。このバッファがあれば、締切前日の障害は致命傷にならなくなります。
習慣2: ローカル保存を徹底する
claude.aiとのやり取りで重要な結果が出たら、必ずコピーしてローカルのWord・メモ・Notion・Evernote等に貼っておく習慣をつけます。Claudeの履歴に残しておけば安心、ではありません。アカウントトラブルや万一のデータ障害で履歴自体が見えなくなる可能性はゼロではないからです。
Claude Codeでファイルを作らせた場合は、もともとローカルのPCに保存されるので問題ありません。問題になりやすいのはclaude.aiのブラウザチャットです。大事な生成結果は必ずダウンロードかコピペでローカル化する、これを習慣化してください。
習慣3: Pro + API の二刀流で保険をかける
業務で頻繁に使うなら、Proプラン1契約+API従量課金用のAPIキー1本を両方持っておくと保険になります。Proが停止してもAPIは動く(あるいは逆)というケースで、APIキーを別のクライアントに貼って、そこから最低限のリクエストを投げる、といった運用ができます。
非エンジニアが自力でAPIを叩くのは少しハードルがあるので、普段は触らないバックアップ口として、キーの発行だけしておくのが現実的です。発行しておくだけならコストはゼロ(使った分しか課金されない)です。APIキーの発行はClaude Console(platform.claude.com)から行えます。APIキーの取り方は Anthropic Console(コンソール)とは|APIキーの取り方・課金の仕組み で、料金の全体像は Claude Code の料金、APIそのものの基礎は Claude API とは|非エンジニア向けの始め方 も合わせてどうぞ。
習慣4: 週次バックアップとチャット履歴の棚卸し
週に1回、月曜の始業時などに先週のClaudeとのやり取りのうち重要なものをローカル保管します。5分もあれば終わる作業です。これで、万一のアカウントトラブルや長時間障害でも、過去の知見が残ります。
習慣5: 社内で「障害発生」を共有するルートを決める
10人以上のチームなら、「Claudeが止まっています」と共有する窓口を決めておくと効率的です。SlackやTeamsの「#ai-status」のような専用チャンネルを用意し、誰か1人が障害を検知したら「今日はClaudeが落ちているようです。会議資料の〆切は1時間後ろ倒し可ですか」と投げるルールを作ります。さらに、前述の status.claude.com の「Subscribe to updates」でSlack/Teams連携を設定しておけば、障害情報がそのチャンネルに自動で流れてくるので、人が常時監視する必要すらなくなります。
個別に全員がパニックになるより、1人(または自動通知)が切り分けて全員に共有する仕組みのほうが組織全体の被害が激減します。中小企業でAI導入を進めているチーム向けに、このあたりの運用ルールを含む内部教育は、AI研修・伴走支援のサービス でも個別にご相談いただけます。
よくある不安と答え
非エンジニアの方からよく受ける、Claude障害まわりの質問をまとめて答えます(いずれも2026年7月時点)。
Q1. 障害中に作業していたチャットのデータは消えますか?
基本的には消えません。claude.aiの会話履歴はAnthropicのサーバー側に保存されており、障害が復旧すると履歴画面から普通に読めます。ただし、障害の真っ最中に生成途中で止まった応答については、完全な応答が保存されない場合があります。重要な生成結果は、応答が完了したらすぐローカルにコピーしておくのが確実です。
Q2. 障害中の時間分、料金は返ってきますか?
Pro プランやMaxプランのサブスクリプション料金は、一般的に障害時間分の返金はありません。サブスクは月単位のサービス提供なので、数時間の停止で日割り返金の対象にはなりにくいのが通例です。ただし、大規模長時間障害があった場合、Anthropicが個別に対応することはあり得ます。API従量課金は「使った分だけ」課金なので、障害中は使えない=課金もされない、という構造です。
Q3. 特定のモデルだけ落ちることはありますか?
よくあります。むしろ2026年6月〜7月は、これが最も多い障害パターンでした。6月5日の障害でも、Opus 4.6 が17分で戻った一方、Opus 4.8 が戻るまでは1時間50分ほどかかるなど、同じ障害でもモデルごとに復旧時刻が違うことが実際に起きています。普段使っているモデルが不調なときは、一段下のモデル(Sonnet 4.6やHaiku 4.5など)に切り替えるだけで作業を続けられることが多いです。
Q4. 障害を完全に避けるために、別のAIに全部移行するべきですか?
必要ありません。どのAIサービスも障害ゼロはあり得ず、移行先でも同じ悩みが発生します。むしろ運用上効率的なのは、メインは使い慣れたClaude1本に集約し、保険として別AIのサブ契約を1本だけ持つ構え方です。複数サービスを常時並行運用するのは、学習コストや切り替えコストで日常業務を圧迫します。
Q5. status.anthropic.com をブックマークしていますが、変えるべきですか?
そのままでも当面は問題ありません。2026年7月時点でも、status.anthropic.com にアクセスすると自動的に status.claude.com へ転送されます(302リダイレクト)。ただし、転送設定はいつ変わるか分からないので、この機会に新しい status.claude.com に貼り替えておくと確実です。
Q6. Claude Code にログインできないのですが、これも障害ですか?
あり得ます。実例として、日本時間2026年7月7日の早朝(4:18〜5:05)には、claude.ai のエラー増加に連動して Claude Code のログイン(ブラウザ経由の認証)までできなくなる障害が発生しました。約47分で復旧しています。Claude Code のログインは裏側で claude.ai の認証の仕組みを使っているため、claude.ai 側の障害に巻き込まれることがあります。ログインできないときも、まず status.claude.com で claude.ai の状態を確認するのが早道です。
Q7. 復旧したかどうかをリアルタイムで知るには?
status.claude.com の進行中の障害表示が「Monitoring(経過観察)」から「Resolved(解決済み)」に変わったら復旧です。ページを何度も再読み込みしなくても、前述の Subscribe to updates でメールやSlackに自動通知を設定しておけば、復旧の瞬間に知らせが届きます。体感の速報性ではX(旧Twitter)で Claude 復旧 と検索するのも補助になりますが、最終確認は公式のResolved表示で行うのが確実です。
Q8. 送信しても Claude が応答しない(返事が止まる)のは障害ですか?
まず本文の3分切り分け(再読み込み→シークレットウィンドウ→モバイル回線→status.claude.com)を試してください。ステータスページが緑のまま応答しない場合は、1つの会話が長くなりすぎているのが原因のことも多く、新しいチャットを立ち上げ直すと動くケースがよくあります。遅い・途中で切れるといった調子が悪い症状だけなら、過負荷による速度低下の可能性が高く、時間を置くか軽いモデルに切り替えるのが有効です。
まとめ——今日のうちにやっておく3つのこと
ここまで読んでいただいたあなたが、今日このまま閉じる前にやっておくと安心なことを3つだけお伝えします。
- status.claude.com をブラウザのブックマークに追加し、「Subscribe to updates」でメールかSlack通知を登録する
- 普段使うモデル(例: Opus 4.8)が落ちたときに切り替える第2のモデル(Sonnet 4.6など)を決めておく
- よく使うClaudeの会話のうち重要なものを1つ、ローカルのフォルダにコピーして保管する
この3つを済ませておくだけで、次に障害が起きたときのパニック時間を大きく減らせます。所要時間は合計3分です。
そして最後にもう一度伝えたいのは、Claude障害は基本的に短時間で復旧するということです。2026年6月〜7月の実績でも、多くは数分〜1時間以内に戻っています。焦らず、この記事の3分切り分けフローに従って、代替手段で仕事を進める。これだけで、非エンジニアでも障害を怖がらずに済むようになります。
経営者・管理職の方へ——AI障害に強いチームの作り方
ここまでの内容は、個人がパニックにならないための手順でした。ですが本当に効くのは、「Claudeが止まっても業務が止まらない仕組み」を組織として持っておくことです。誰がどう切り分け、どう共有し、どの代替に逃がすか——これを社内ルールに落とし込めば、障害は事故ではなく「想定内の小さな足踏み」になります。
非エンジニアの経営者・管理職の方が、自社にAIを導入しつつこうした運用ルール(障害対応・情報管理・教育)まで一気に整えるための実務ガイドを1冊にまとめました。
障害対応だけでなく、最初の1本のAIをどう選び、誰に使わせ、どう社内に定着させるかまでを、専門用語なしで解説しています。社内展開のたたき台としてそのまま使えます。
参考リファレンス
- Claude 公式ステータスページ: status.claude.com(旧 status.anthropic.com から自動転送)
- 関連記事: Claude の稼働状況を確認する方法
- 関連記事: Claude を Chrome で使う方法
- 関連記事: Claude Opus とは何か
- 関連記事: Claude と ChatGPT の違い
- 関連記事: Anthropic Console(コンソール)とは|APIキーの取り方・課金の仕組み
- 関連記事: Claude Cowork とは
- 関連記事: Claude Teamプラン 企業向け完全ガイド



