
ハーネスエンジニアリングとは何か
2026年2月、OpenAIが発表したSWE-bench(AIがソフトウェアの課題を解決するベンチマーク)の分析レポートで、衝撃的な事実が明らかになりました。
AIの性能を最も大きく改善したのは、モデルのアップグレードではなく「ハーネスの改善」だった——。
ハーネスとは、もともと馬具(手綱・くつわ)のこと。馬の能力をいくら高めても、手綱がなければ暴走します。AIエージェントも同じで、どれだけ賢いモデルを使っても、適切な制御の仕組みがなければ期待通りの成果は出ません。
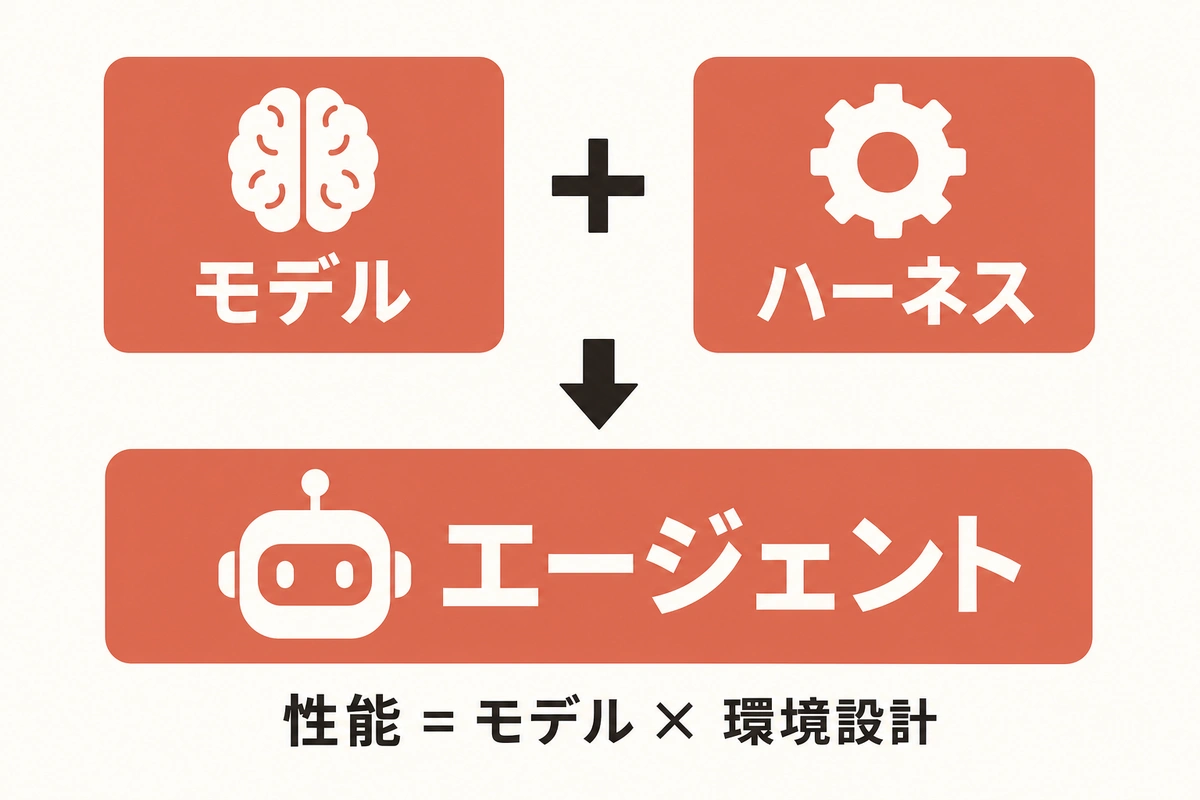
この「AIモデルを正しく動かすための環境設計」を体系化したのが、ハーネスエンジニアリングです。
公式で表すと:
Agent = Model + Harness
つまり、AIエージェントの実力は「モデルの性能 × 環境の設計」で決まるということです。
なぜ今、ハーネスエンジニアリングが注目されるのか
プロンプトエンジニアリングの限界
これまでは「プロンプトを工夫すればAIの出力が良くなる」という考え方が主流でした。確かにプロンプトの書き方は大事です。しかし、実務で使い込むと壁にぶつかります。
- 毎回同じ指示を書くのが面倒(「ですます調で」「競合他社名は伏字で」など)
- AIが途中で方針を忘れる(長い会話になると初期の指示が薄れる)
- チーム内で品質がバラバラ(人によってプロンプトの質が違う)
- 間違いに気づかない(AIが自信満々に誤った出力をしても、そのまま通る)
これらはすべて、プロンプトだけでは解決できない問題です。環境(ハーネス)の設計で解決する必要があります。
SWE-benchが証明した事実
OpenAIが2026年2月に公開したSWE-bench分析レポート(https://openai.com/index/introducing-swe-bench-verified/)によると、SWE-benchのスコア改善のうち、モデル変更による改善よりもハーネス改善による改善のほうが大きかったケースが複数確認されています。つまり、最新モデルに乗り換えるよりも、今使っているモデルの環境設計を見直すほうが、成果が出る可能性が高いのです。
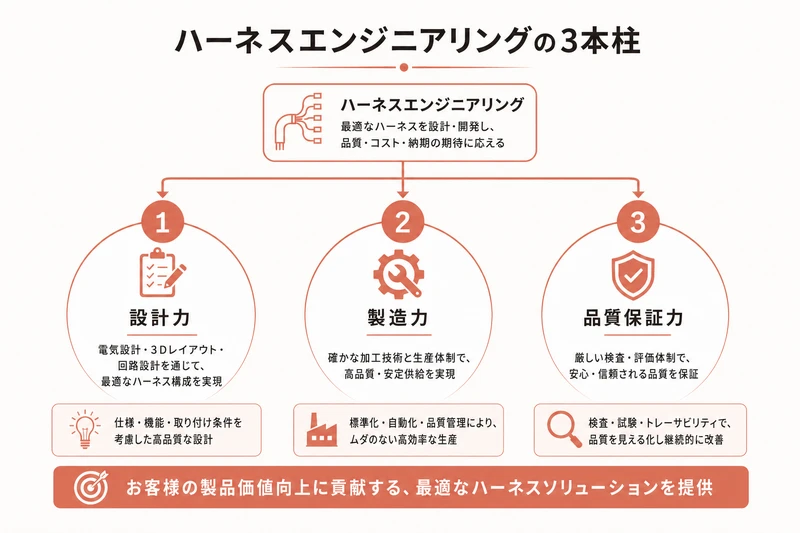
ハーネスエンジニアリングの3本柱
ハーネスエンジニアリングは、大きく3つの要素で構成されます。
1. ルールファイル(行動規範の明文化)
AIに「どう振る舞ってほしいか」をファイルに書いておく仕組みです。
人間の新入社員にマニュアルを渡すのと同じ発想です。毎回口頭で説明するのではなく、ルールを文書化しておけば、誰が指示を出しても同じ品質の仕事が返ってきます。
各ツールでのルールファイルの配置場所:
| AIツール | ファイル名 | 配置場所 |
|---|---|---|
| Claude Code | CLAUDE.md | プロジェクトのルート |
| Kiro | steering/*.md | .kiro/steering/ |
| OpenAI Codex | AGENTS.md | プロジェクトのルート |
Claude Code の場合、CLAUDE.md というファイルを作業フォルダに置くだけで、起動時に自動的に読み込まれます。
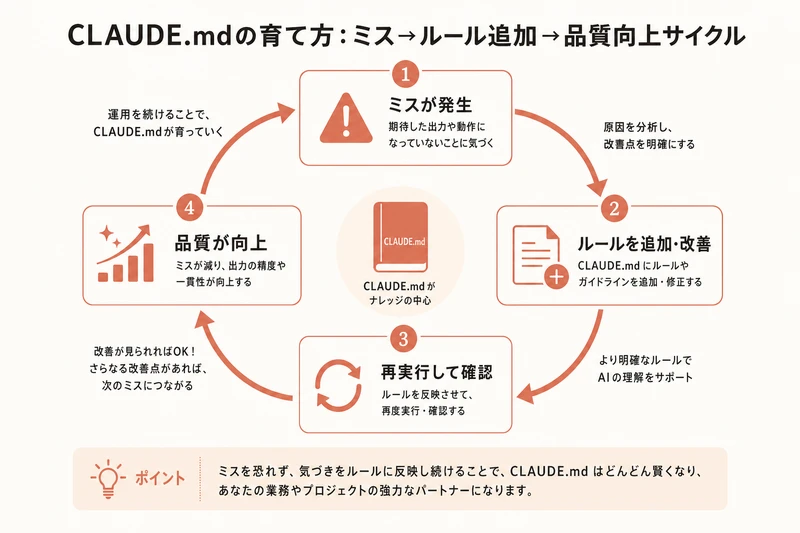
効果的なCLAUDE.mdの書き方
60行以内が目安です。長すぎるとAIが重要な部分を見落とします。以下の3セクションに絞りましょう:
# プロジェクトの概要
- このプロジェクトは〇〇のためのもの
- ターゲットは〇〇(非エンジニア/中小企業の経営者 等)
# コーディング規約
- 文体: ですます調
- 競合他社名は使わない
- 数字は必ず根拠を添える
# やってはいけないこと
- 社外秘情報を出力に含めない
- 推測で数字を作らない
ポイントは「AIが間違えやすいこと」に特化してルールを書くことです。当たり前のことを書いても効果は薄いです。過去にAIが犯したミスをルールに追加していく「育てるCLAUDE.md」が最も効果的です。
営業チーム向けCLAUDE.mdの実例:
# 営業部 Claude利用ルール
- 提案書は「ですます調」、社内向けは「だである調」
- 競合他社名(A社、B社)は伏字にする
- 見積金額は必ず「税別」と明記
- 顧客の個人名は入力しない(役職+イニシャルで代替)
- 提案書の構成: 課題→解決策→効果→費用→スケジュール
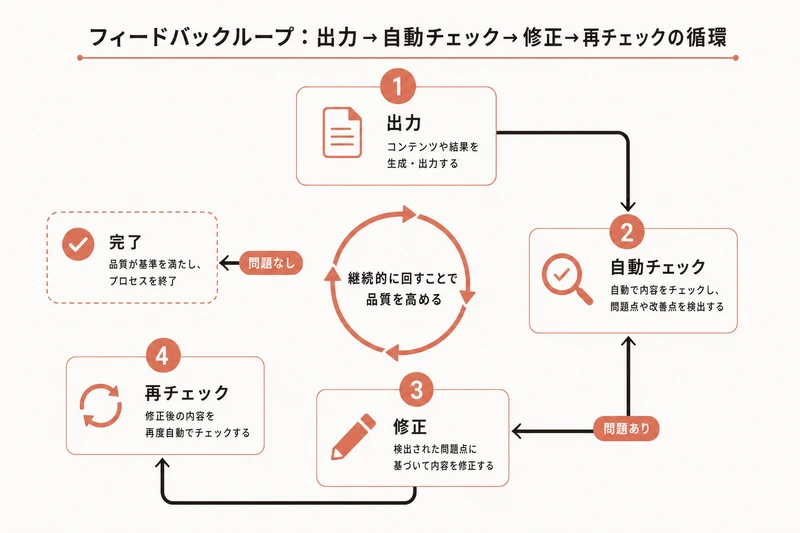
2. フィードバックループ(自動検証の仕組み)
AIの出力を自動的にチェックし、問題があれば修正を促す仕組みです。
人間のレビュアーがいなくても、機械的にチェックできるポイントは自動化してしまう考え方です。
Claude Code の Hooks 機能
Claude Codeには「フック(Hooks)」という機能があります。「〇〇したら自動的に△△が動く」という設定です。
例えば:
- ファイル保存時 → 表記揺れチェックを自動実行
- コミット前 → 禁止ワード(社名・機密情報)のスキャン
- 文書作成後 → 文字数カウント+文体チェック
これにより、AIが間違えても人間が気づく前に自動的に検出・修正されます。
テスト駆動の考え方
より高度な運用では、テスト駆動開発(TDD)の原理をAIに適用します。
- まず「正しい出力の条件」を定義する(テスト)
- AIにその条件を満たす出力を作らせる
- テストが通らなければ、AIに修正を指示する
- 通るまで繰り返す
この仕組みにより、AIは「テストに合格するまで自分で修正し続ける」ようになります。人間が一つひとつチェックする必要がなくなるのです。
3. コンテキスト管理(記憶と進捗の管理)
AIは長い会話になると、最初に伝えた情報を忘れてしまうことがあります。進捗や判明した制約を記録ファイルに残す仕組みです。
progress.md の活用
Anthropic(Claude の開発元)は、大きなタスクを進める際に「progress.md」ファイルで進捗を管理することを推奨しています。
# 進捗管理
## 完了した作業
- 月次レポートのテンプレート作成
- 前月比の計算式を確認
## 次にやること
- グラフの作成
- 上司向けサマリーの追記
## 判明した制約
- 売上データは税抜表記で統一
- グラフは3色以内
このファイルがあることで、AIが「何をやって、何がまだで、何に気をつけるべきか」を常に参照できます。
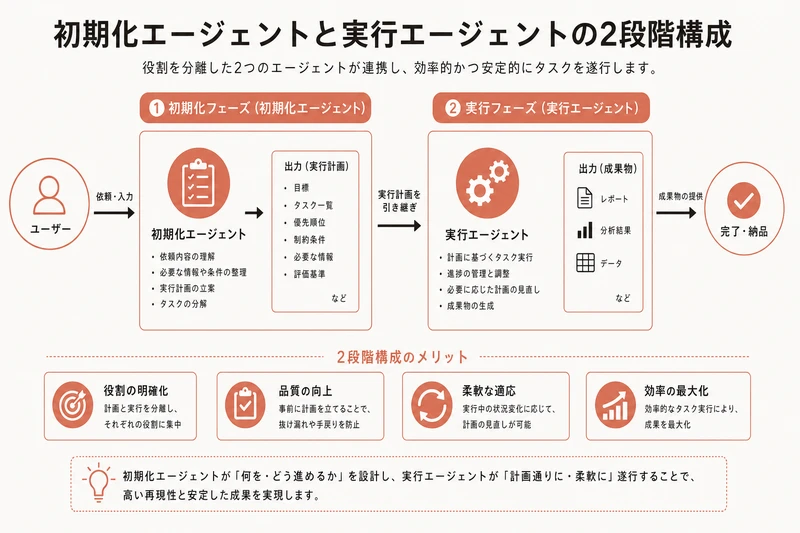
初期化エージェントとコーディングエージェントの分離
Anthropicは、大きなタスクを処理する際に2段階のエージェント構成を推奨しています:
- 初期化エージェント: タスクの全体像を把握し、作業計画を立てる
- 実行エージェント: 計画に従って具体的な作業を進める
これにより、実行中に「そもそも何をやるんだっけ?」という迷走を防げます。
実践的な実装パターン
パターン1: エージェントの責務分離
一人のAIに全てを任せるのではなく、役割ごとに別のAIエージェントを用意する方法です。
実際の運用例(Speaker Deckの事例より):
| エージェント名 | 役割 |
|---|---|
| tdd-web-engineer | テスト駆動で実装する |
| code-reviewer | コーディング規約の準拠を確認する |
| perf-reviewer | セキュリティとパフォーマンスを検証する |
| spec-reviewer | 仕様との整合性を検証する |
| task-issue-creator | タスクを適切な粒度に分割する |
このように役割を分けることで、1つのAIが「作りながらチェックする」という矛盾を避けられます。人間の組織でも「作った本人がレビューする」のは効果が薄いのと同じです。
パターン2: カスタムスキル(スラッシュコマンド)
よく使うワークフローをコマンド一発で呼び出せるようにする方法です。
Claude Code では .claude/commands/ フォルダにファイルを置くだけで、独自のスラッシュコマンドが作れます。
実例:
/dev→ 仕様把握 → テスト計画 → 実装 → 品質チェック(一連の流れを自動実行)/review→ 3つのレビューエージェントが並列でチェック/fix-pr→ 指摘事項を修正 → 再レビュー(最大3回リトライ)
これにより、複雑なワークフローを誰でも同じ品質で実行できるようになります。
パターン3: MCP(外部ツール連携)
AIに「目」と「手」を与える仕組みです。
MCP(Model Context Protocol)を使うと、AIがブラウザでWebページを確認したり、Slackにメッセージを送ったり、データベースを検索したりできるようになります。
実用例:
- ブラウザでページを開いてスクリーンショットを撮り、表示崩れを検出
- Google Sheetからデータを取得して分析レポートを作成
- Slackの特定チャンネルを監視して日次サマリーを作成
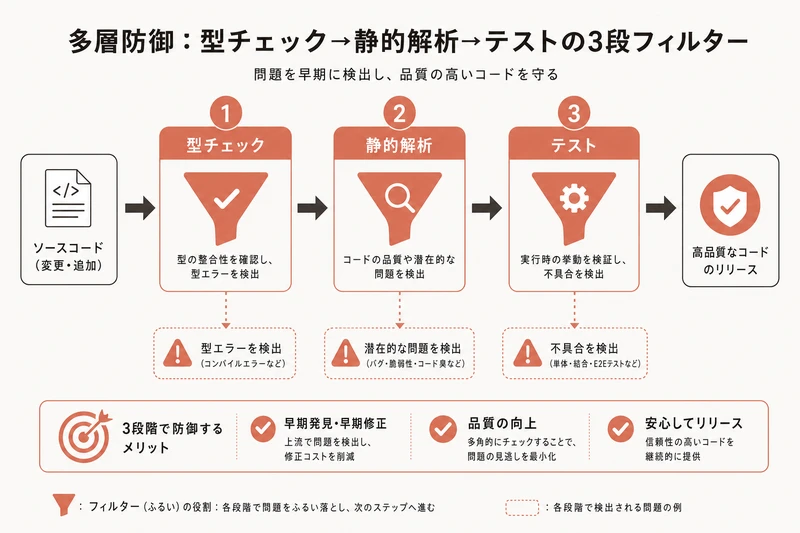
パターン4: 多層防御(ガードレール)
AIの出力品質を複数のレイヤーで段階的にチェックする方法です。
第1層: 型チェック → そもそも形式が正しいか
第2層: 静的解析 → ルール違反がないか
第3層: テスト → 期待通りの動作をするか
各レイヤーが異なる観点で問題を検出し、人間に届く前にフィルタリングします。最終的に人間が確認するのは、3層のフィルターを通過した成果物だけ。レビューの負担が大幅に減ります。
プロンプトエンジニアリングとの違い
| 観点 | プロンプトエンジニアリング | ハーネスエンジニアリング |
|---|---|---|
| 対象 | AIへの指示文 | AIを取り巻く環境全体 |
| 持続性 | 毎回書く(使い捨て) | 一度設定すれば継続的に効く |
| 再現性 | 人によって質が変わる | 誰が使っても同じ品質 |
| 自動化 | 手動 | 自動チェック・自動修正 |
| チーム共有 | 個人のスキルに依存 | ファイルとして共有可能 |
| 例え | 「馬への声かけの工夫」 | 「手綱・鞍・柵の設計」 |
プロンプトエンジニアリングが「AIへの話しかけ方の工夫」だとすれば、ハーネスエンジニアリングは「AIが正しく走れるレールと安全柵を敷く」ことです。
両方重要ですが、組織でAIを活用する場合、ハーネスの設計のほうが投資対効果が高いです。一人のプロンプトの達人に頼るより、全員が使えるハーネスを整備するほうが持続的です。
非エンジニアがハーネスエンジニアリングを始める3ステップ
ハーネスエンジニアリングは、プログラミングができなくても始められます(CLAUDE.mdはテキストファイル1つ書くだけです)。非エンジニアでも、以下の3ステップで始められます。
ステップ1: CLAUDE.md を書く(15分)
作業フォルダに CLAUDE.md ファイルを作り、「自分の仕事のルール」を箇条書きで書きます。
- 自分の役職と担当業務
- 文書の文体ルール
- よく使う用語の表記統一
- 絶対にやってはいけないこと
これだけで、毎回の説明コストがゼロになります。
ステップ2: スラッシュコマンドを1つ作る(30分)
最もよく依頼する作業を、スラッシュコマンドにします。月次レポート、議事録要約、メール下書きなど、月2回以上やる作業が候補です。
.claude/commands/monthly-report.md を作って、いつもの指示を書いておくだけです。
ステップ3: AIのミスをルールに追加する(継続)
AIが間違えるたびに、CLAUDE.md にルールを1行追加します。「この間違いは二度としないでね」というルールを蓄積していくことで、AIが日に日に賢くなる効果があります。
この3ステップを1ヶ月続けるだけで、AIの出力品質は劇的に変わります。月に15〜30時間の作業時間削減が見込めます。
ハーネスエンジニアリングを導入した企業の成果は導入事例で確認できます。
ハーネスエンジニアリングの今後
ハーネスエンジニアリングは、2026年のAI活用における最重要トピックの一つです。
今後は、以下のような進化が予想されます:
- ハーネスのテンプレート化: 業種別・職種別のCLAUDE.mdテンプレートが整備される
- 自動ハーネス最適化: AIがハーネス自体を改善する(メタ最適化)
- チーム標準ハーネス: 企業ごとの「AIの使い方標準」がハーネスとして定義される
- ハーネスのマーケットプレイス: 効果的なハーネス設定を売買・共有する仕組み
モデルの進化は待つしかありませんが、ハーネスの改善は今すぐ始められます。
まとめ
ハーネスエンジニアリングの本質は、「AIを制御する仕組みの設計」です。
- ルールファイル(CLAUDE.md)で行動規範を明文化する
- フィードバックループ(Hooks・テスト)で自動検証する
- コンテキスト管理(progress.md)で記憶を外部化する
この3つを整備するだけで、同じAIモデルでも出力品質が劇的に変わります。最新モデルに乗り換えるより、今のモデルのハーネスを見直すほうが、コストも低く効果も大きい——それがSWE-benchの分析が示した事実です。
Claude Works では、ハーネスエンジニアリングの考え方を研修に取り入れています。CLAUDE.mdの書き方からスラッシュコマンドの設計まで、実務で使えるレベルまで伴走します。



