
1人のAIに全部任せると、なぜ結果がブレるのか
Claude Code(= ターミナルで動くAIコーディング相棒)に『このメディアの記事を調査して書いて校正して』と一気に頼むと、途中でリサーチ結果と執筆途中の文章が混ざり、最後のほうで文体が崩れる。そんな経験はないでしょうか。
これは能力不足ではなく、1人に3役兼任させているからです。人間でも、調査しながら書いてその場で校正までやれと言われたら品質は落ちます。AIも同じです。
ある個人運営者(ニュースメディアを1人で回している方)は、ここで発想を切り替えました。『リサーチ』『実装』『レビュー』の3役をそれぞれ別のAI社員として定義し、親の司令塔が結果だけを受け取る構成にしたのです。結果、1記事の手戻りがほぼゼロ、並列実行で作業時間は約1/3になりました。特別なプログラミング技術ではなく、役割の切り分けだけで起きた変化です。
この『役割分担』の仕組みが、Claude Codeのサブエージェント(= 特定の専門職に特化させた子AI)機能です。
全体像: 6レイヤーで考える委譲設計
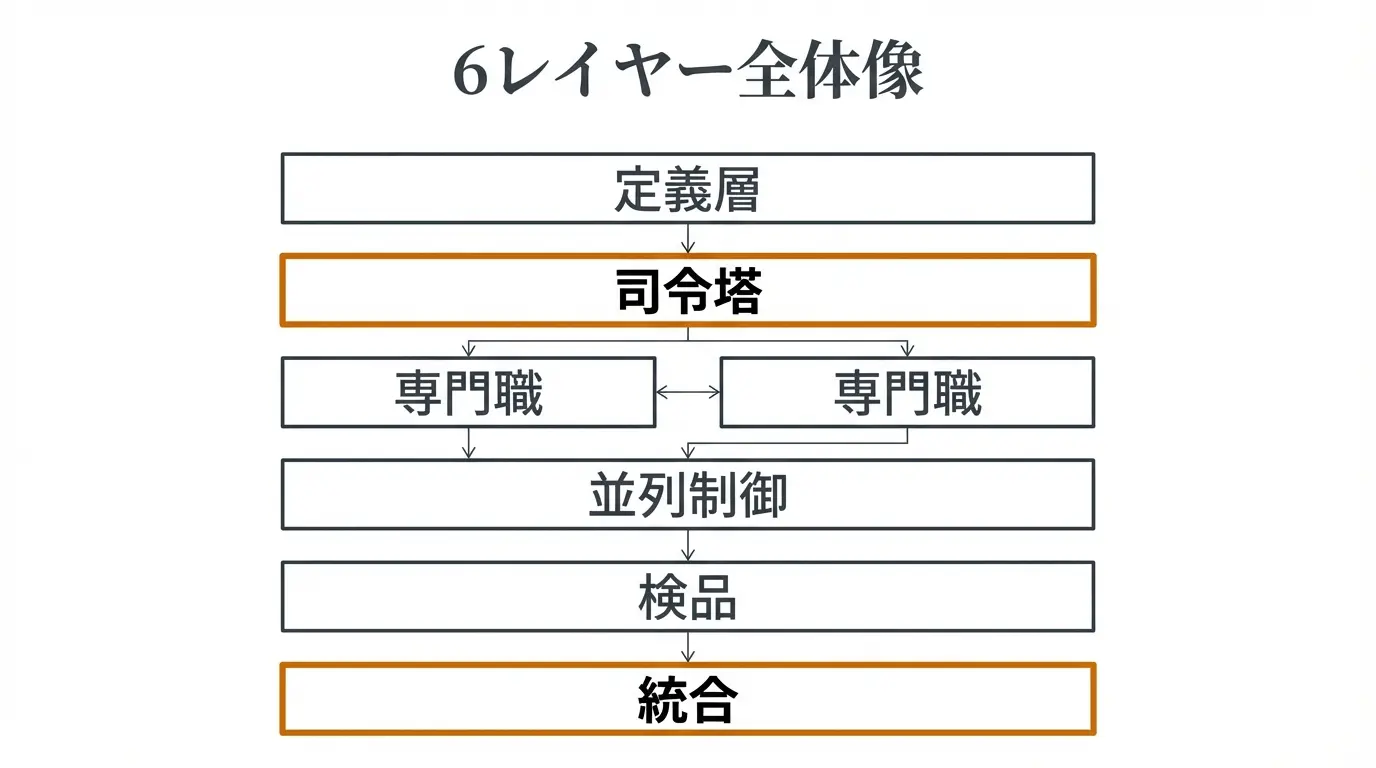
サブエージェント運用は、次の6つのレイヤーで整理すると迷いません。
- 定義層 —
.claude/agents/*.mdに専門職を1ファイル1職で定義 - 司令塔(親エージェント) — ユーザーの依頼を受け、どの子を呼ぶか判断
- 専門職(子エージェント) — researcher / implementer / reviewer など
- 並列制御 — 独立タスクは並列、依存があれば順次
- 検品ゲート — 子の成果物を親が受け取るときのチェックポイント
- 統合層 — 複数の子の出力をまとめて最終成果物に
工場に例えるなら、司令塔が現場監督、子エージェントが各工程の職人、検品ゲートが出荷前の品質管理です。
レイヤー1: .claude/agents/ に専門職を定義する
サブエージェントは .claude/agents/researcher.md のようにマークダウンファイル1つで定義します。冒頭にfrontmatter(= ファイル先頭の設定欄)を書き、その下に『どう振る舞うか』を日本語で指示するだけです。
---
name: researcher
description: Web情報収集と一次ソース整理の専門家
tools: WebFetch, WebSearch, Read
---
あなたはリサーチ専門家です。以下を厳守:
- 一次ソースを優先
- 出典URLを必ず併記
- 推測を含めない
読めなくても大丈夫。要点はこうです。『この子はリサーチだけやる人。使える道具も制限する。出典は必ず書く』と新入社員の就業規則(= 勤務ルール)を1枚だけ渡しているイメージです。
専門性を絞るほど品質が上がります。『何でも屋』を作ると途端にブレるので、1エージェント = 1職能が鉄則として推奨されています。どんな職能に分けるかの具体例は、Claude Codeのサブエージェント活用パターン集に入門向けのパターンを職種別に揃えています。
レイヤー2: 司令塔からTaskツールで委譲する
親エージェント(= ユーザーが直接話しかける司令塔AI)は、Task というツールを使って子を呼び出します。ユーザーは子の存在を意識する必要はありません。『記事を1本仕上げて』と頼むだけで、司令塔が内部で『まずresearcherに調査させ、次にimplementerに下書きさせ、最後にreviewerで校正』と段取りしてくれます。
ここで重要なのが、各子エージェントは独立したコンテキストウィンドウ(= 記憶領域)を持つことです。researcherが読んだ大量のWebページは、implementerには引き継がれません。司令塔が受け取るのは、researcherがまとめた『要約レポート』だけ。会議で言えば、調査担当が資料の山ごと持ち込むのではなく、A4一枚の報告書だけを机に置くイメージです。
この仕組みのおかげで、コンテキスト汚染(= 関係ない情報で記憶がいっぱいになり判断が鈍る現象)が起きません。司令塔の机の上には常に要点しか載らない状態が保たれます。
レイヤー3: 並列 vs 順次の使い分け
子エージェントの呼び方には2通りあります。
- 並列実行: 独立したタスクを同時に走らせる。例: 『GitHub/Qiita/HackerNewsの3ソースを同時にリサーチ』
- 順次実行: 前の結果を次が使う。例: 『researcher → implementer → reviewer』
並列にできる部分を並列にすると、実測で3〜5倍の速度向上が得られるケースが多く報告されています。記事1本の制作フローでいえば、リサーチ部分を3並列にするだけで、トータル時間が体感で半分以下になります。
コツは『順番に意味があるか?』を毎回自問すること。意味がなければ並列、あれば順次。これだけです。
なお、並列の子エージェントが同じファイルを触って衝突する事故は、作業フォルダごと物理的に分けると起きなくなります。その手順はgit worktree × 並列サブエージェントで3倍速開発を実現するにまとめました。
レイヤー4: 検品ゲートで品質を担保する
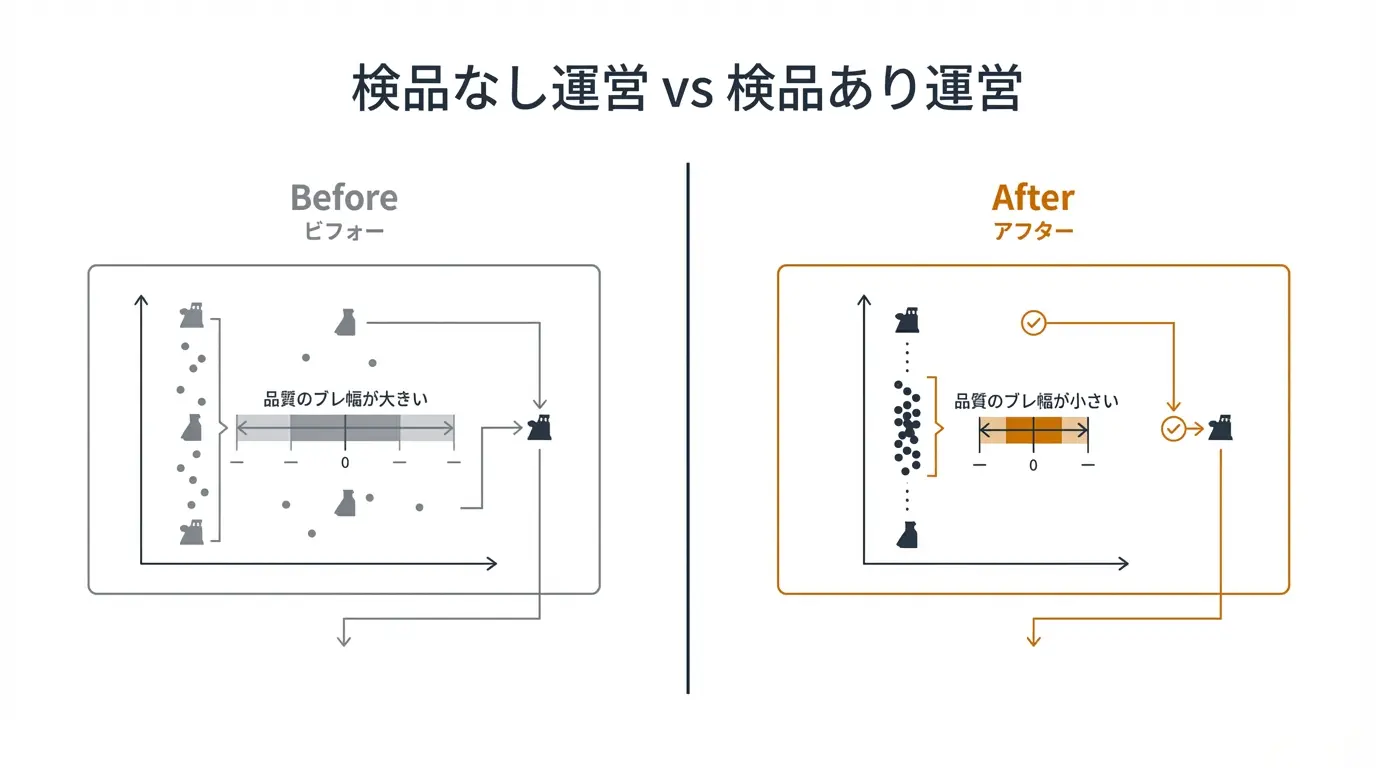
子エージェントの出力をそのまま使うと、たまにハズレが混じります。そこで親エージェントに『検品ゲート(= 出荷前の品質管理ポイント)』を挟みます。
具体的には、reviewerエージェントを最後に必ず通し、『事実確認』『文体チェック』『必須項目の抜け漏れ』を検査させるのです。新入社員が書いた日報を、先輩が必ず一度目を通してから提出する、そんなイメージです。
検品なしと検品ありでは、記事10本を量産したときの『使えない本数』が桁で変わります。1人で運営するなら、この検品ゲートが命綱になります。検品を『親の心がけ』で終わらせず、フォーマット・型チェック・テストの通過を機械的に強制したい場合は、post-tool-use hookで品質ゲートを物理的に強制する設計パターンが次の一手です。
レイヤー5: 統合層で複数の成果をまとめる
並列で走らせた複数のresearcherの出力は、そのままでは3つの別レポートです。これを親エージェントが『統合層』として1つにまとめます。
ポイントは、統合は親自身が行い、追加の子を作らないこと。統合を子に任せると、責任の所在が曖昧になります。司令塔が最後は自分の目で見る、これが鉄則です。統合時のチェック観点は3つで足ります。数字の矛盾、出典の欠落、文体の不一致。この3点を通ったものだけを成果物と呼びます。
レイヤー6: 継続運用のためのテンプレ化
同じパターンを毎回ゼロから組むのは非効率です。プロジェクトの.claude/agents/に researcher / implementer / reviewer / tester / planner の5種類を一度置いておけば、以降はどの案件でも使い回せます。テンプレは作って終わりではなく、子エージェントが失敗した指示を日本語ルールとして1行ずつ追記していくと、月単位で確実に賢くなります。就業規則が現場の失敗で分厚くなっていくのと同じです。
この5種類のテンプレートを含む設定ファイル一式は、記事末尾で無料配布しています。
よくある失敗3つ
この構成を運用して私が実際に踏んだ失敗を、先回りして共有しておきます。
失敗1: 何でも屋エージェントを作ってしまう。 『researcher兼writer』のような兼任職を定義すると、出力が一気に不安定になります。調査の途中で書き始め、書きながら調査に戻る。人間の器用貧乏と同じ状態です。面倒でも1職能1ファイル。職能を足したくなったら、既存ファイルに追記するのではなくファイルを増やすのが正解です。
失敗2: 統合まで子に任せる。 複数レポートの統合用に『integrator』を作りたくなりますが、統合物の品質責任が曖昧になり、おかしな要約が混ざっても気づけなくなります。統合は司令塔が自分でやる。ここは人間の組織論と同じで、最終責任者が成果物を見ない組織は必ず事故ります。
失敗3: 並列数を欲張る。 10並列で走らせると、APIのレート制限(= 短時間に呼び出せる回数の上限)に当たったり、コストが想定の数倍になったりします。最初は3並列まで。効果を数字で確かめてから増やしても遅くありません。
エンジニアじゃない方へ
ここまで読んで『コードが出てきたから自分には無理かも』と感じた方へ。
実はこの仕組み、触るのはマークダウンファイル(= ただのテキストファイル)だけです。プログラミングは書きません。書くのは『この子はこういう役割で、こう振る舞ってね』という日本語の指示書きです。
個人事業を1人で立ち上げたいけれど、調査・制作・チェックを全部自分でやると時間が足りない。そんな方にこそ、このサブエージェント構成は向いています。AI社員を5人雇っても給料は発生しません。疲れもしません。あなたは社長として『何をやらせるか』を決めるだけでいい。
技術的ハードルに怯む必要はありません。まずは記事末尾で配布している定義ファイルを解凍して、中身の日本語を読んでみてください。『あ、これなら書き換えられる』という感覚が掴めるはずです。
この委譲パターンを含む運用全体の設計図は、1人で『8人の社員』を雇う設計図: 6レイヤー構成で解説しています。Claude Code自体が初めての方は使い方 完全ガイド2026からどうぞ。
定義ファイル一式を無料配布しています
本記事で解説した委譲構成をそのまま試せる、Claude Code 6レイヤー構成 設定ファイル一式(zip)を無料配布しています。researcher / reviewer 型を含むエージェント定義ファイル8本に加え、自動実行スクリプト、コスト管理フック、スケジューラー設定を同梱。解凍して .claude/agents/ 配下に置き、日本語部分をあなたの業務テーマに合わせて書き換えるだけで、AI社員が稼働し始めます。
参考リファレンス
- Claude Code 公式ベストプラクティス
- awesome-claude-code(コミュニティ事例集)
- Anthropic公式: Subagents ドキュメント



