
データベースの基本 — Webアプリの「記憶」を理解する
バイブコーディング入門 — 第18回
前回のおさらいと、今回のテーマ
前回(第17回)では、セキュリティの基本を学んだ。HTTPSによる通信の暗号化、XSS・SQLインジェクション・CSRFという3大攻撃手法、そしてAIにセキュリティレビューを依頼するテンプレート。アプリを公開する前に最低限チェックすべきことがわかった。
その中で「SQLインジェクション」という攻撃を学んだ。データベースへの問い合わせ文を改ざんする攻撃だった。しかし、そもそも「データベース」とは何なのか。
あなたが12人の税理士事務所の所長だとしよう。バイブコーディングで顧問先管理アプリを作り始めた。AIに「顧問先の情報を保存して、検索できるようにしたい」と伝えたら、AIがこう返してきた。
「Supabaseにテーブルを作成します。clients テーブルに company_name、representative、contract_date、monthly_fee カラムを設定します。外部キーで contacts テーブルとリレーションを張りますね」
テーブル。カラム。外部キー。リレーション。何を言っているのかさっぱりわからない。でも、AIが自信たっぷりに進めているから、とりあえず「はい」と答えてしまう。
この「とりあえず、はい」が危ない。データベースの構造を理解していないと、次のような問題が起きる。
- AIが作ったテーブル構造に問題があっても気づけない
- データが増えたときに動作が極端に遅くなる
- 必要なデータを取り出すときに、AIへの指示がうまく伝わらない
- 第17回で学んだSQLインジェクションのリスクを正しく評価できない
今回は、バイブコーダーが最低限知っておくべきデータベースの基礎を解説する。
今回学ぶこと:
- データベースとは何か(Excelとの違い)
- テーブル・行・列の構造
- SQLの基本(SELECT, INSERT, UPDATE, DELETE)
- リレーション(テーブル同士のつながり)
- Supabaseとは何か、なぜバイブコーディングで使われるのか
- AIにデータベース設計を依頼するテンプレート
第2回の3層構造の知識と、第17回のSQLインジェクションの知識が、ここで一本の線につながる。
データベースとは何か — アプリの「記憶」
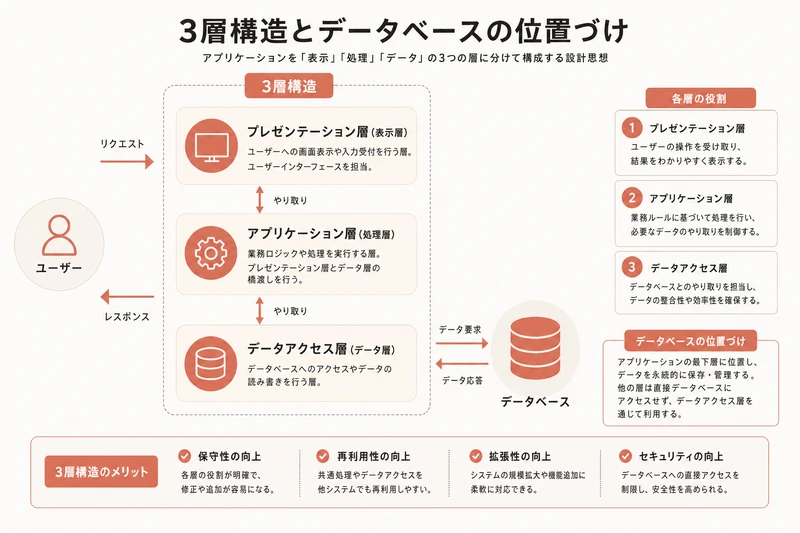
第2回で、Webアプリは3層構造で動いていると学んだ。フロントエンド(見た目)、バックエンド(処理)、データベース(記憶)の3つだ。
データベースは、この3層目にあたる「記憶」の部分だ。
人間に例えてみよう。フロントエンドは「顔」、バックエンドは「脳」、データベースは「記憶」だ。あなたが誰かに「田中さんの電話番号は?」と聞いたとき、脳が記憶から情報を探し出して、口で答える。Webアプリも同じだ。ブラウザ(フロントエンド)が「田中さんの情報を見せて」とリクエストし、サーバー(バックエンド)がデータベースから探し出して返す。
データベースがなければ、アプリは何も覚えられない。ログイン情報、顧客データ、商品リスト、注文履歴、すべてが消えてしまう。ページを閉じて開き直すたびに、まっさらな状態に戻る。
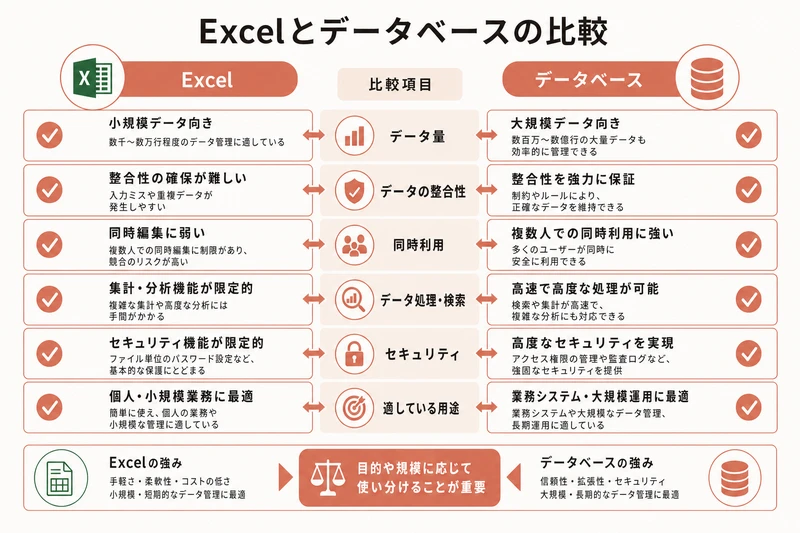
Excelとデータベースの違い
データベースと聞いて、Excelのスプレッドシートを思い浮かべた方は多いだろう。実際、構造は似ている。行と列でデータを整理する点は同じだ。
しかし、決定的な違いが3つある。
1つ目: 同時アクセスへの対応。Excelは基本的に1人が1つのファイルを開いて作業する。複数人が同時に同じセルを編集すると、データが壊れることがある。データベースは、100人、1,000人が同時にアクセスしても、データの整合性(つじつまが合った状態)を保つ仕組みが備わっている。
2つ目: データ量への対応。Excelは数万行を超えると動作が重くなる。データベースは、数百万行、数千万行のデータを扱っても高速に検索できる。顧問先100社の情報なら体感差はないが、顧問先ごとに月次仕訳1,000件、10年分で12万件となると、Excelでは限界がある。
3つ目: プログラムからの操作。ExcelをWebアプリから自動的に読み書きするのは手間がかかる。データベースは、プログラムから「このデータを取ってきて」「この行を更新して」と命令するのが前提の設計になっている。だからWebアプリのバックエンドと相性がよい。
テーブル・行・列 — データベースの基本構造
データベースの中身は「テーブル」で整理されている。テーブルとは、日本語で言えば「表」だ。Excelのシートに近いイメージだと思ってよい。
税理士事務所の例で考えてみよう。顧問先管理アプリには、次のようなテーブルがあるとする。
clients テーブル(顧問先一覧):
| id | company_name | representative | contract_date | monthly_fee |
|---|---|---|---|---|
| 1 | 株式会社山田商事 | 山田太郎 | 2024-04-01 | 50000 |
| 2 | 有限会社鈴木工業 | 鈴木一郎 | 2023-10-15 | 80000 |
| 3 | 合同会社佐藤デザイン | 佐藤花子 | 2025-01-10 | 35000 |
このテーブルには、3つの重要な概念がある。
行(ロウ、row): 横の1行がデータ1件を表す。上の表では、「株式会社山田商事」の情報が1行目、「有限会社鈴木工業」が2行目だ。行のことを「レコード」とも呼ぶ。Excelの行と同じ感覚だ。
列(カラム、column): 縦の1列がデータの種類を表す。「company_name」が会社名、「monthly_fee」が月額顧問料、という具合だ。列のことを「フィールド」とも呼ぶ。Excelの列見出しと同じ感覚だ。
id: 各行を一意に(重複なく)識別するための番号だ。「主キー」(プライマリーキー、Primary Key)と呼ばれる。なぜ必要なのか。もし「山田商事」という会社が2社あったとき、会社名だけでは区別できない。id=1 と id=4 のように、番号で区別する。Excelの行番号に似ているが、データベースのidは削除しても番号が詰まらない(1, 2, 3 の2を削除しても、1, 3 のまま)。
型(データの種類)を決める
Excelでは、1つのセルに文字でも数字でも日付でも自由に入れられる。データベースは違う。各列には「型」(データの種類)を事前に決める。
主な型:
- text(テキスト): 文字列。会社名、住所、メモなど
- integer(インテジャー): 整数。金額、数量、年齢など
- boolean(ブーリアン): 真偽値。「はい」か「いいえ」の2択。「契約中かどうか」など
- date(デイト): 日付。契約日、期限日など
- timestamp(タイムスタンプ): 日時。「2026年4月16日 14:30:00」のように時刻まで含む
なぜ型を決めるのか。型を決めておくと、間違ったデータが入るのを防げる。monthly_fee(月額顧問料)をinteger型にしておけば、誰かが間違えて「五万円」と文字で入れようとしたときに、データベースがエラーを出して防いでくれる。Excelだと「五万円」がそのまま入ってしまい、集計のときにエラーになる。
SQL — データベースへの「お願い」の書き方
SQLは、データベースに対して「お願い」をするための言語だ。第17回でSQLインジェクションを学んだとき、SQL文が少し出てきた。今回は、もう少し詳しく見ていこう。
少しだけコードが出てくるが、意味を理解できればよい。自分で書く必要はない。バイブコーディングでは、AIがSQL文を書いてくれる。あなたが知っておくべきなのは「AIが書いたSQL文が何をしているのか」を読み取る力だ。
SQLの基本操作は4つだ。この4つを覚えれば、データベースで行われていることの大部分がわかる。
SELECT — データを取ってくる
SELECT(セレクト)は「このデータを取ってきて」というお願いだ。最も頻繁に使う操作だ。
SELECT company_name, monthly_fee FROM clients
これは「clientsテーブルから、会社名と月額顧問料を取ってきて」という意味だ。結果は:
| company_name | monthly_fee |
|---|---|
| 株式会社山田商事 | 50000 |
| 有限会社鈴木工業 | 80000 |
| 合同会社佐藤デザイン | 35000 |
条件を付けることもできる。
SELECT company_name, monthly_fee FROM clients WHERE monthly_fee >= 50000
WHERE(ウェア)は「条件」だ。「月額顧問料が5万円以上の顧問先だけ取ってきて」という意味になる。結果は山田商事と鈴木工業の2件だ。
並び順を指定することもできる。
SELECT company_name, monthly_fee FROM clients ORDER BY monthly_fee DESC
ORDER BY(オーダーバイ)は「並べ替え」、DESC(デスク)は「降順」(大きい順)だ。月額顧問料が高い順に並ぶ。
INSERT — データを追加する
INSERT(インサート)は「新しいデータを追加して」というお願いだ。
INSERT INTO clients (company_name, representative, contract_date, monthly_fee)
VALUES ('株式会社田中建設', '田中次郎', '2026-04-01', 60000)
これは「clientsテーブルに、田中建設の情報を1行追加して」という意味だ。idは自動で採番されるので、指定しなくてよい。
UPDATE — データを更新する
UPDATE(アップデート)は「既存のデータを変更して」というお願いだ。
UPDATE clients SET monthly_fee = 55000 WHERE id = 1
これは「clientsテーブルで、id=1の行(山田商事)の月額顧問料を55,000円に変更して」という意味だ。
WHEREを付け忘れると、全行が更新されてしまう。UPDATEとDELETEでWHEREを忘れるのは、データベース操作で最も怖いミスの1つだ。
DELETE — データを削除する
DELETE(デリート)は「データを削除して」というお願いだ。
DELETE FROM clients WHERE id = 2
これは「clientsテーブルから、id=2の行(鈴木工業)を削除して」という意味だ。
DELETEもWHEREを忘れると全行が消える。「DELETE FROM clients」とだけ書くと、全顧問先のデータが消滅する。第17回のSQLインジェクションで「最悪の場合、テーブルを全削除できる」と書いたのは、このことだ。
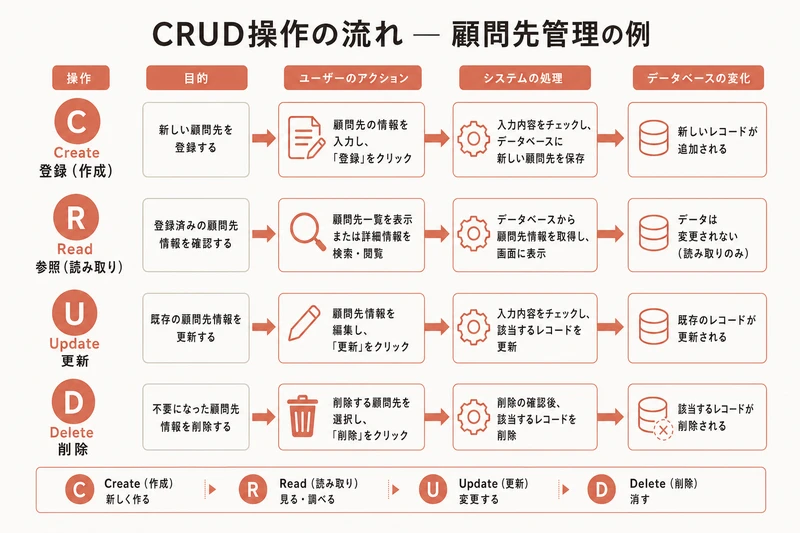
CRUD — 4つの操作をまとめて
この4つの操作は、頭文字を取ってCRUD(クラッド)と呼ばれる。
- C: Create(作成)→ INSERT
- R: Read(読み取り)→ SELECT
- U: Update(更新)→ UPDATE
- D: Delete(削除)→ DELETE
Webアプリで行われるデータ操作は、ほぼこの4つに分類できる。顧問先を「登録する」「一覧で見る」「情報を修正する」「解約して削除する」。すべてCRUDだ。
リレーション — テーブル同士のつながり
ここからが、Excelとデータベースの最大の違いだ。
Excelでは、1つのシートにすべての情報を詰め込むことが多い。顧問先の基本情報も、担当者の連絡先も、面談の記録も、同じシートの右にどんどん列を増やしていく。
データベースでは、情報を複数のテーブルに分けて管理する。そして、テーブル同士を「つなげる」。この「つながり」をリレーション(関係)と呼ぶ。
なぜ分けるのか。1つの表にすべてを入れると、データの重複が起きるからだ。
例を見てみよう。顧問先「山田商事」には、担当者が3人いるとする。経理の佐藤さん、総務の田中さん、社長の山田さんだ。
1つのテーブルにすべて入れると:
| company_name | monthly_fee | contact_name | contact_role | contact_phone |
|---|---|---|---|---|
| 株式会社山田商事 | 50000 | 佐藤美穂 | 経理 | 03-1111-2222 |
| 株式会社山田商事 | 50000 | 田中健一 | 総務 | 03-1111-3333 |
| 株式会社山田商事 | 50000 | 山田太郎 | 社長 | 03-1111-1111 |
「株式会社山田商事」と「50000」が3回繰り返されている。月額顧問料が変わったとき、3行すべてを更新しなければならない。1つ更新し忘れたら、データの不整合(つじつまが合わない状態)が起きる。
データベースでは、こう分ける。
clients テーブル:
| id | company_name | monthly_fee |
|---|---|---|
| 1 | 株式会社山田商事 | 50000 |
contacts テーブル:
| id | client_id | name | role | phone |
|---|---|---|---|---|
| 1 | 1 | 佐藤美穂 | 経理 | 03-1111-2222 |
| 2 | 1 | 田中健一 | 総務 | 03-1111-3333 |
| 3 | 1 | 山田太郎 | 社長 | 03-1111-1111 |
contacts テーブルの client_id が「1」になっている。これは clients テーブルの id=1(山田商事)を指している。この client_id のことを「外部キー」(フォーリンキー、Foreign Key)と呼ぶ。外部キーは「別のテーブルの行を指し示すポインター」だ。
こうすれば、山田商事の月額顧問料が変わっても、clients テーブルの1行を更新するだけで済む。担当者が何人いても、会社情報は1箇所だけだ。
1対多の関係
上の例では、1つの顧問先に複数の担当者がいる。これを「1対多」の関係と呼ぶ。1つの「親」に対して、複数の「子」がぶら下がる構造だ。
Webアプリでよく出てくる1対多の例:
- 1人のユーザーが複数の注文を持つ(ECサイト)
- 1つの会社が複数の従業員を持つ(人事管理)
- 1つのプロジェクトが複数のタスクを持つ(タスク管理)
- 1人の顧問先が複数の月次報告を持つ(税理士事務所アプリ)
バイブコーディングでAIが「外部キーでリレーションを張ります」と言ったとき、それはこの「1対多の関係を設定する」という意味だ。
JOINでテーブルを結合する
テーブルを分けたのはいいが、「山田商事の担当者一覧を見たい」というときはどうするのか。分かれているデータを1つにまとめて表示する必要がある。
このとき使うのがJOIN(ジョイン)だ。JOINは「2つのテーブルを、共通のキーで結合する」操作だ。
SELECT clients.company_name, contacts.name, contacts.role
FROM clients
JOIN contacts ON clients.id = contacts.client_id
WHERE clients.id = 1
これは「clientsテーブルとcontactsテーブルを、clients.idとcontacts.client_idが一致する行同士でつなげて、山田商事(id=1)の会社名・担当者名・役職を取ってきて」という意味だ。
結果は:
| company_name | name | role |
|---|---|---|
| 株式会社山田商事 | 佐藤美穂 | 経理 |
| 株式会社山田商事 | 田中健一 | 総務 |
| 株式会社山田商事 | 山田太郎 | 社長 |
JOINは最初は複雑に感じるかもしれないが、イメージとしては「2つのExcelシートを、共通の番号を使って1つの表にまとめる」操作だと思えばよい。
Supabase — バイブコーダーの味方
ここまでデータベースの基礎を学んだ。では、バイブコーディングでは具体的にどうやってデータベースを使うのか。
答えは、多くの場合「Supabase(スーパーベース)」だ。
Supabaseは、データベースを含む一連のサービスを、Webブラウザから簡単に使えるようにしたサービスだ。正式には「BaaS(バース、Backend as a Service)」と呼ばれるカテゴリに属する。バックエンドの機能を、サービスとして提供してくれるものだ。
なぜSupabaseがバイブコーディングで人気なのか
理由は3つある。
1つ目: データベースの構築が不要。通常、データベースを使うには、サーバーにデータベースソフトをインストールし、設定し、管理する必要がある。Supabaseを使えば、Webブラウザでプロジェクトを作るだけで、データベースがすぐに使える状態になる。
2つ目: SQL文を書かなくてもよい。Supabaseには「クエリビルダー」と呼ばれる仕組みがあり、JavaScriptのコードでデータベースを操作できる。
たとえば、「月額顧問料が5万円以上の顧問先を取ってくる」という操作は:
SQL文で書くと:
SELECT * FROM clients WHERE monthly_fee >= 50000
Supabaseのクエリビルダーで書くと:
supabase.from('clients').select('*').gte('monthly_fee', 50000)
どちらも同じことをしている。クエリビルダーの方が「プログラムのコード」に馴染みやすく、AIもこちらの形式でコードを生成することが多い。そして第17回で学んだ通り、クエリビルダーは自動でSQLインジェクション対策をしてくれる。
3つ目: 認証機能が付いている。第16回で学んだ認証(ログイン)の仕組みが、Supabaseには最初から含まれている。メール・パスワード認証、Googleログイン、パスワードリセットなど、自分でゼロから作らなくてよい。
Supabaseのダッシュボード
SupabaseにはWebブラウザで使える管理画面(ダッシュボード)がある。ここで、Excelのように視覚的にテーブルの中身を見たり、行を追加したり、構造を変更したりできる。
バイブコーディングでは、AIがコードからSupabaseを操作する。しかし、「今テーブルにどんなデータが入っているか」を確認したいときは、このダッシュボードを開けばよい。SQLを知らなくても、データの状態をExcel感覚で確認できる。
RLS — 行レベルのアクセス制御
Supabaseには「RLS(アールエルエス、Row Level Security)」という機能がある。日本語で言えば「行レベルのセキュリティ」だ。
これは「誰がどの行を見られるか」を制御する仕組みだ。たとえば、「ログインしているユーザーは、自分が作成したデータだけを見られる」「管理者はすべてのデータを見られる」といったルールを設定できる。
なぜこれが重要なのか。RLSを設定しないと、Supabaseのデータベースにアクセスできる人は、すべてのデータを自由に読み書きできてしまう。顧問先管理アプリで、AさんがBさんの顧問先データを見られてしまったり、悪意のあるユーザーが他人のデータを削除できてしまったりする。
バイブコーディングでSupabaseを使うとき、AIに「RLSは設定してありますか?」と確認することを強く推奨する。なお、Supabaseに貯めたデータをSlackやNotionなど社内の他ツールと直接つなぎたくなったら、MCPサーバーを自作して社内DBをClaudeに繋ぐ方法が次のステップになる。
バイブコーダーのデータベース設計テンプレート
バイブコーディングでAIにデータベース設計を依頼するとき、次のテンプレートを使うと精度が上がる。
このアプリで管理したいデータは以下の通り。適切なテーブル設計をしてほしい。管理したいデータ:
- (例: 顧問先の会社情報 — 会社名、代表者名、住所、契約日、月額顧問料)
- (例: 担当者の連絡先 — 名前、役職、電話番号、メールアドレス、どの会社の人か)
- (例: 面談記録 — 日時、参加者、議題、メモ、次回アクション)
設計にあたって以下を守ってほしい:
- データの重複を避けるために、適切にテーブルを分けてリレーションを設定してほしい
- 各テーブルにidの主キーを設定してほしい
- 作成日時と更新日時のカラムを全テーブルに付けてほしい
- Supabase上に作成してほしい
- RLS(Row Level Security)を設定して、ログインユーザーのみアクセスできるようにしてほしい
- 作成するテーブルの一覧と、各テーブルのカラム(列名・型・説明)を一覧表で見せてほしい
設計ができたら、テーブル間の関係(1対多など)も図で説明してほしい。
ポイントは最後の「一覧表で見せてほしい」と「関係も図で説明してほしい」だ。AIが作った設計を、自分の目で確認できる形にしてもらう。何を言っているかわからないまま先に進むのが一番危険だ。
インデックス — 検索を速くする仕組み
データが少ないうちは気にならないが、データが増えてきたときに重要になるのが「インデックス」だ。
インデックスは、日本語で言えば「索引」だ。辞書の後ろにある「あいうえお順の索引」を想像してほしい。辞書で「データベース」という言葉を探すとき、1ページ目から順番にめくっていたら途方もない時間がかかる。索引を使えば「た行」→「て」→「データベース: 234ページ」と、すぐにたどり着ける。
データベースのインデックスもまったく同じ原理だ。「この列はよく検索に使うから、索引を作っておいてね」とデータベースに指示しておくと、検索が格段に速くなる。
たとえば、顧問先を会社名で検索することが多いなら、company_name列にインデックスを作る。顧問先が1,000社あっても、インデックスがあれば一瞬で見つかる。インデックスがないと、1,000行を1行ずつ順番にチェックすることになる。
バイブコーディングでは、AIに「よく検索する列にインデックスを付けてほしい」と伝えればよい。具体的にどの列がよく検索されるかは、あなたの業務を知っているあなた自身が一番わかっている。「会社名で検索することが多い」「契約日で絞り込むことが多い」と伝えれば、AIが適切にインデックスを設定してくれる。
よくある不安と答え
SQLを覚えなければいけないのか
覚えなくてもバイブコーディングはできる。AIがSQL文やSupabaseのコードを書いてくれるからだ。ただし、SELECT・INSERT・UPDATE・DELETEの4つが「何をしているか」を読み取れると、AIとのやりとりの精度が格段に上がる。「この操作はSELECTだから、データは変わらないな」「DELETEか、消えるのか。WHERE条件は正しいか」と判断できるようになる。
データが消えたらどうなるのか
Supabaseには自動バックアップ機能がある。Proプラン(月額25ドル、約3,800円)以上なら、毎日自動でバックアップが取られる。万が一データが消えても、バックアップから復元できる。ただし、無料プランでは自動バックアップはないので、重要なデータを扱うなら有料プランへの移行を検討した方がよい。
Supabaseの無料プランでどこまでできるか
Supabase無料プランの主な制限(2026年4月時点):
- データベースのストレージ: 500MB
- 月間アクティブユーザー: 50,000人
- プロジェクト数: 2つ
- 自動バックアップ: なし
- 1週間操作がないとデータベースが一時停止する
12人の税理士事務所のアプリなら、無料プランで十分に動く。顧問先100社、各社の担当者・面談記録を合わせても、500MBには到底届かない。ユーザー数も50,000人の制限には遠い。ただし、1週間操作がないと一時停止する点は注意が必要だ。業務で毎日使うアプリなら問題ないが、月に数回しか使わないアプリなら有料プランの方が安心だ。
ExcelからSupabaseにデータを移行できるか
移行できる。Supabaseのダッシュボードには、CSVファイル(カンマ区切りの表データ)をインポートする機能がある。ExcelのデータをCSV形式で保存し、Supabaseにインポートすればよい。AIに「ExcelのデータをSupabaseに移行したい。CSVインポートの手順を教えて」と聞けば、具体的な手順を案内してくれる。
まとめ
データベースは、Webアプリの「記憶」だ。Excelと似た構造(テーブル・行・列)だが、同時アクセス・大量データ・プログラムからの操作に強い。SQL(SELECT, INSERT, UPDATE, DELETE)はデータベースへの「お願い」の書き方で、4つの操作を覚えればデータベースで何が行われているかの大部分がわかる。テーブルを分けてリレーション(外部キー)でつなぐことで、データの重複を防ぐ。Supabaseはこれらの仕組みを、バイブコーダーが使いやすい形で提供してくれるサービスだ。
テーブル設計からデプロイまで、アプリ作りの全工程を体系的に押さえたい方にはClaude Code 完全マニュアル(全84ページ・無料PDF)を配布している。この連載の副読本として使ってほしい。
次回は「環境変数とデプロイ — 『ローカルで動く』から『世界に公開』へ」。アプリを自分のパソコンで動かしている段階から、インターネット上に公開する方法を解説する。環境変数(APIキーなどの秘密情報の管理方法)と、Vercelを使ったデプロイの手順を学ぶ。
参考リファレンス
- 前回: 第17回「HTTPS・セキュリティの基本 — 『知らなかった』では済まない」
- 次回: 第19回「環境変数とデプロイ — ローカルで動くのにVercelで500エラーになる理由」
- 第2回「フロントエンド・バックエンド・データベース — 3層構造を理解する」
- バイブコーディング入門 カリキュラム(/vibe-coding)



