
REST APIの設計パターン — エンドポイントの規則性を知る
バイブコーディング入門 — 第12回
前回までのおさらいと、今回のテーマ
前回(第11回)では、CORSエラーについて学んだ。ブラウザが異なるオリジン(プロトコル+ドメイン+ポートの組み合わせ)へのリクエストをセキュリティのためにブロックする仕組みだった。
ここまでのシリーズで、HTTPの主要な要素を一通り学んできた。
- 第5回: URL(手紙の宛先)
- 第6回: JSON(手紙の中身の書き方)
- 第7回: HTTPメソッド(手紙の用件 — GET・POST・PUT・DELETE)
- 第8回: ステータスコード(返事のスタンプ — 200・404・500)
- 第9回: HTTPヘッダ(封筒の付帯情報)
- 第10回: ステートレスとCookie・セッション・JWT(記憶の仕組み)
- 第11回: CORSエラー(異なる住所への手紙がブロックされる仕組み)
これらの知識がそろったところで、いよいよ「API全体の設計パターン」を見ていく。
バイブコーディングでAIにアプリを作ってもらうと、/api/tasks、/api/users/123、/api/projects/5/members といったURLが自動的に生成される。これらのURLには規則性がある。REST API(レスト・エーピーアイ)という設計パターンに基づいているからだ。
この規則性を知っておくと、3つのメリットがある。
- DevToolsのNetworkタブに並ぶ通信ログが「読める」ようになる
- エラーが起きたとき、どのAPIで何が失敗したか的確にAIに伝えられる
- AIに「こういうAPIを追加して」と依頼するとき、具体的に指示できる
RESTとは何か — URLでモノを、メソッドで動作を表す
REST(Representational State Transfer)は、WebのAPI(アプリケーション同士がやりとりするための窓口)を設計するときの考え方だ。2000年にロイ・フィールディングという研究者が提唱したもので、現在のWebアプリのほとんどがこの考え方に従っている。
難しい定義は省略して、実用上の核心だけを押さえよう。REST APIの設計パターンは、たった2つのルールに集約される。
ルール1: URLで「何を」操作するかを表す ルール2: HTTPメソッドで「どう」操作するかを表す

第7回でHTTPメソッド(GET・POST・PUT・DELETE)を学んだとき、「同じURLに対して、メソッドを変えることで異なる操作ができる」という話をした。REST APIは、まさにこの考え方を体系化したものだ。
リソースとエンドポイント — APIの住所体系
REST APIでは、操作の対象を「リソース」と呼ぶ。タスク、ユーザー、請求書、プロジェクト — アプリの中で管理するデータの種類が、それぞれリソースだ。
そして、各リソースにアクセスするためのURLを「エンドポイント」と呼ぶ。APIの住所のようなものだ。
日常業務に例えてみよう。あなたの会社に「社員名簿」「プロジェクト台帳」「請求書ファイル」がそれぞれ棚に整理されているとする。
- 社員名簿の棚 → /api/employees
- プロジェクト台帳の棚 → /api/projects
- 請求書ファイルの棚 → /api/invoices
棚全体を指すのが「コレクション」(一覧)で、棚から1つのファイルを取り出すときはID番号を付ける。
- 社員名簿の全員分 → /api/employees
- 社員番号42の情報 → /api/employees/42
- 全プロジェクト → /api/projects
- プロジェクトID 7番 → /api/projects/7
このように、REST APIのURLは「何の棚の、どれ」を表現する住所体系になっている。
5つの基本操作 — CRUDとREST
データに対する操作は、突き詰めると4種類しかない。この4つをまとめてCRUD(クラッド)と呼ぶ。
- C = Create(作る)
- R = Read(読む)
- U = Update(更新する)
- D = Delete(削除する)
REST APIでは、これにHTTPメソッドを対応させる。タスク管理アプリを例にすると、次のようになる。
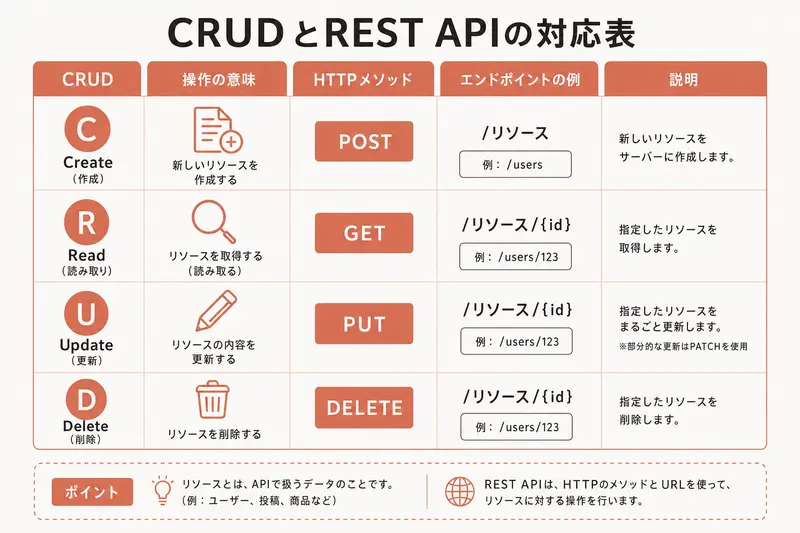
この5つのパターンが、REST APIの基本形だ。どんなWebアプリでも、ほぼこの5つの組み合わせで成り立っている。
いくつか注意点がある。
一覧取得(GET /api/tasks)と個別取得(GET /api/tasks/5)は、同じGETメソッドだがURLが違う。IDが付いているかどうかで「全部」と「1つ」を区別する。
新規作成(POST)はIDを指定しない。まだ存在しないデータなので、IDはサーバーが自動で割り振る。
更新(PUT)と削除(DELETE)は必ずIDを指定する。「どれを」更新・削除するのか特定する必要があるからだ。
実際のAPIを読んでみる — タスク管理アプリの場合
バイブコーディングでAIに「タスク管理アプリを作って」と頼んだとする。AIが生成するAPIは、だいたい次のような構造になる。
DevToolsのNetworkタブを開いてアプリを操作すると、こんな通信が並ぶ。
アプリを開いたとき: GET /api/tasks → 200(タスク一覧を取得、成功)
タスクをクリックしたとき: GET /api/tasks/3 → 200(タスク3番の詳細を取得、成功)
新しいタスクを追加したとき: POST /api/tasks → 201(新しいタスクを作成、成功)
タスクの内容を編集したとき: PUT /api/tasks/3 → 200(タスク3番を更新、成功)
完了したタスクを削除したとき: DELETE /api/tasks/3 → 200(タスク3番を削除、成功)
DevToolsのNetworkタブに並ぶ通信を見て「GET /api/tasks が404を返している」と分かれば、「タスク一覧の取得に失敗している。APIのエンドポイントが見つからないようだ」とAIに伝えられる。
「POST /api/tasks が500を返している」なら、「新しいタスクの作成でサーバーエラーが起きている」と分かる。
HTTPメソッドとURL、ステータスコードの組み合わせで、何がどう失敗したかが一目で分かるのがREST APIの利点だ。
ネスト(入れ子)のURL — 親子関係を表す
リソースに親子関係がある場合、URLをネスト(入れ子)にすることがある。
たとえば、プロジェクト管理アプリで「プロジェクトの中にタスクがある」という構造を考える。
- プロジェクト一覧 → GET /api/projects
- プロジェクト7番のタスク一覧 → GET /api/projects/7/tasks
- プロジェクト7番のタスク15番 → GET /api/projects/7/tasks/15
URLを左から読むと、「プロジェクトの中の、7番の、タスクの中の、15番」という住所になっている。ファイルシステムのフォルダ構造と同じ考え方だ。
別の例として、ECサイト(通販サイト)のAPIを考えてみよう。
- ユーザー一覧 → GET /api/users
- ユーザー42番の注文一覧 → GET /api/users/42/orders
- ユーザー42番の注文8番 → GET /api/users/42/orders/8
- ユーザー42番の注文8番の明細 → GET /api/users/42/orders/8/items
ネストが深くなりすぎると(3階層以上)読みにくくなるので、通常は2階層までに収めるのが一般的だ。3階層以上になる場合は、AIに「このAPIの構造を整理したい」と相談してみるとよい。
クエリパラメータ — 条件を指定する
第5回(URL)で学んだクエリパラメータ(?の後ろに付く条件)は、REST APIでも活用される。一覧取得のGETリクエストに条件を付けたいときに使う。
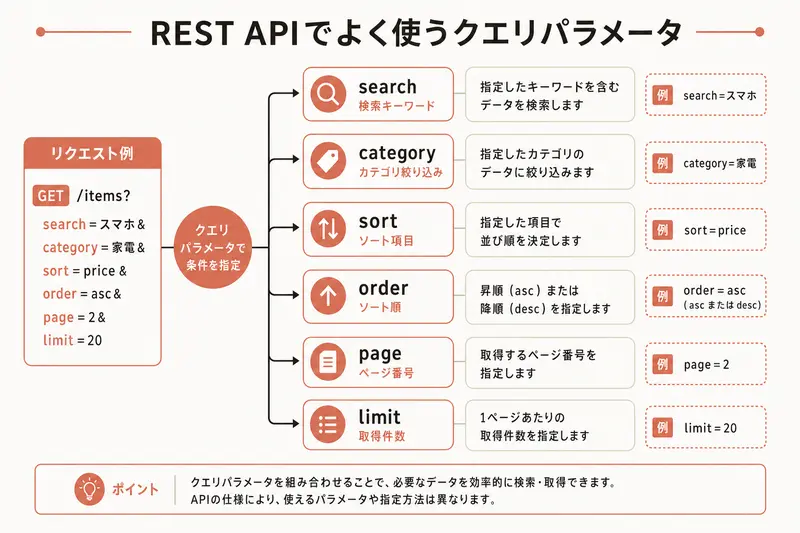
絞り込み(フィルタリング): GET /api/tasks?status=pending 「ステータスが pending(未完了)のタスクだけを取得する」
並び替え(ソート): GET /api/tasks?sort=created_at&order=desc 「作成日時の新しい順に並べて取得する」
ページ送り(ページネーション): GET /api/tasks?page=2&limit=20 「1ページ20件で、2ページ目を取得する」
検索: GET /api/tasks?q=報告書 「報告書という文字を含むタスクを検索する」
これらは組み合わせることもできる。
GET /api/tasks?status=pending&sort=due_date&limit=10 「未完了のタスクを期限順に10件取得する」
クエリパラメータはあくまで「条件」であり、リソースの種類やIDはURLのパス部分(/api/tasks/5 のような部分)で指定する。この使い分けがREST APIの規則だ。
レスポンスの形 — APIが返すJSONの読み方
REST APIのレスポンス(サーバーからの返答)は、ほとんどの場合JSON形式だ。第6回で学んだJSON(キーと値のペア)の知識がここで活きてくる。
一覧取得のレスポンス例:
{
"tasks": [
{ "id": 1, "title": "企画書を提出する", "status": "done" },
{ "id": 2, "title": "見積もりを確認する", "status": "pending" },
{ "id": 3, "title": "議事録を共有する", "status": "pending" }
],
"total": 25,
"page": 1,
"limit": 20
}
tasks — タスクの配列(リスト)。各タスクにはid、title、statusなどの情報が含まれている。 total — タスクの総数。ページ送りの計算に使う。 page、limit — 現在のページと1ページあたりの件数。
個別取得のレスポンス例:
{
"id": 3,
"title": "議事録を共有する",
"status": "pending",
"description": "4月15日の営業会議の議事録をSlackで共有する",
"due_date": "2026-04-18",
"created_at": "2026-04-15T09:30:00Z",
"updated_at": "2026-04-15T10:15:00Z"
}
一覧では省略されていた description(詳細説明)やdue_date(期限)が含まれている。一覧は「概要」、個別取得は「詳細」というパターンが多い。
新規作成のレスポンス例:
POST /api/tasks に { "title": "月次レポートを作成する" } を送ると、サーバーが自動でIDや作成日時を付与して返してくれる。
{
"id": 26,
"title": "月次レポートを作成する",
"status": "pending",
"created_at": "2026-04-16T14:00:00Z"
}
ステータスコードが 201(Created)で返ってくれば、作成が成功した証拠だ。
AIが生成したAPIの構造を確認する方法
バイブコーディングでAIにアプリを作ってもらったとき、APIの全体像を把握するにはどうすればよいだろうか。3つの方法がある。
方法1: DevToolsのNetworkタブで実際の通信を見る アプリの各画面を操作しながらNetworkタブを見ると、どんなAPIが呼ばれているか分かる。これが最も確実な方法だ。
方法2: AIに「このアプリのAPI一覧を教えて」と聞く AIはコードの構造を把握しているので、エンドポイントの一覧をまとめて教えてくれる。
方法3: ファイル構造から推測する Next.jsの場合、app/api/ フォルダの中にあるroute.tsファイルが各エンドポイントに対応している。
app/api/tasks/route.ts → GET /api/tasks と POST /api/tasks app/api/tasks/[id]/route.ts → GET /api/tasks/:id と PUT /api/tasks/:id と DELETE /api/tasks/:id
[id] のように角括弧で囲まれたフォルダ名は「動的パラメータ」を意味する。第5回で学んだパスパラメータだ。
AIへの依頼テンプレート
REST APIの知識を使って、AIに的確に依頼する例を紹介する。
新しいAPIを追加してほしいとき: 「請求書を管理するAPIを追加してほしい。GET /api/invoices で一覧取得、GET /api/invoices/:id で個別取得、POST /api/invoices で新規作成。各請求書には client_name(取引先名)、amount(金額)、due_date(支払期限)、status(未払い/支払済み)のフィールドが必要。」
既存のAPIにフィルタリングを追加してほしいとき: 「GET /api/tasks にステータスで絞り込む機能を追加してほしい。GET /api/tasks?status=pending で未完了のタスクだけを返すようにしたい。」
エラーを報告するとき: 「タスクの編集画面で保存ボタンを押すと、DevToolsで PUT /api/tasks/3 が 500 を返している。Request Bodyには { "title": "更新後のタイトル", "status": "done" } が入っている。PUT /api/tasks/3 のサーバー側の処理に問題があるかもしれない。」
REST APIの規則を知っていると、「APIが動かない」という漠然とした報告の代わりに、「PUT /api/tasks/3 が500を返す」という具体的な報告ができる。AIにとって、後者のほうが圧倒的に対処しやすい。
よくある不安と答え
REST APIの設計ルールは絶対に守らないといけないのか
RESTは「ガイドライン」であり、法律のような厳格なルールではない。実際のアプリでは、RESTの原則から少し外れた設計になることもある。たとえば、検索機能を POST /api/search にする(GETではなくPOSTを使う)といったケースだ。バイブコーディングでは、AIがRESTの原則に沿った設計をしてくれることが多いが、100%完璧にRESTに従っている必要はない。重要なのは「一貫性」だ。
URLのリソース名は英語でないといけないのか
慣習として英語が使われる。/api/tasks、/api/users、/api/invoices のように。これはURLにマルチバイト文字(日本語など)を含めると技術的なトラブルが起きやすいためだ。リソース名の英語が分からないときは、AIに「〇〇を管理するAPIを作りたいが、URLはどうすればよいか」と聞けば適切な名前を提案してくれる。
APIのバージョニング(/api/v1/tasksのようなURL)は何を意味するのか
APIの仕様を大きく変えるとき、古い仕様を使っているクライアント(フロントエンドやスマホアプリ)が壊れないように、バージョン番号を付けることがある。/api/v1/tasks が旧バージョン、/api/v2/tasks が新バージョン、というように。バイブコーディングで個人的にアプリを作る範囲では、バージョニングを気にする必要はほとんどない。
PATCHとPUTの違いは何か
第7回で触れなかったが、HTTPにはPATCHというメソッドもある。PUTは「データ全体を置き換える」、PATCHは「データの一部だけを更新する」という違いがある。たとえば、タスクのステータスだけを変えたい場合、PATCHのほうが意味的には正確だ。ただし、実際のアプリではPUTとPATCHの区別が曖昧なことも多い。AIが生成したコードがPUTでもPATCHでも、動作に問題がなければそのままで構わない。
まとめ
REST APIは「URLで何を、メソッドでどうする」を表現する設計パターンだ。/api/tasks のようなURLがリソース(操作対象)を示し、GET・POST・PUT・DELETEのメソッドが一覧取得・作成・更新・削除を表す。この規則性を知っていると、DevToolsのNetworkタブの通信ログが読めるようになり、AIへのエラー報告や機能追加の依頼が具体的かつ的確になる。バイブコーディングでは、この規則を自分で設計する必要はない。AIが設計してくれる。あなたの役割は、AIが生成したAPIの構造を読み解いて、適切にフィードバックすることだ。
次回は「APIリクエストとレスポンスの実践 — DevToolsで一連の流れを追う」。これまで学んだURL、メソッド、ステータスコード、ヘッダ、JSON、REST APIの知識を総動員して、DevToolsで実際の通信を一つひとつ追いかける実践回だ。
参考リファレンス
- MDN Web Docs「REST」— REST の基本概念についての解説
- 前回: 第11回「CORSエラーを理解する — なぜブラウザがリクエストをブロックするのか」(/articles/vc-011)
- 次回: 第13回「APIリクエストとレスポンスの実践 — DevToolsで一連の流れを追う」(/articles/vc-013)
- バイブコーディング入門 カリキュラム(/vibe-coding)