
Webの歴史を5分で — なぜ今の形になったのか
バイブコーディング入門 — 第3回
前回までのおさらいと、今回のテーマ
第1回では、Webアプリは「手紙のやりとり」(リクエストとレスポンス)で動いていることを解説した。第2回では、Webアプリを構成する3つの役割 — フロントエンド(ホール)、バックエンド(キッチン)、データベース(冷蔵庫)— を紹介した。
ここまでで「Webアプリが何でできているか」は分かった。でも、1つ疑問が残っているはずだ。
「なぜ、こんなに複雑なのか?」
CursorやClaude Codeでアプリを作ると、大量のファイルが生成される。フロントエンド用のファイル、バックエンド用のファイル、設定ファイル、APIのファイル。なぜページを表示するだけなのに、こんなに多くのファイルが必要なのか。
答えは「歴史」にある。Webは30年以上かけて進化してきた。最初はもっとシンプルだった。それが、時代のニーズに合わせて変化した結果、今の形になった。
今回は、Webの歴史を4つの時代に分けて解説する。「なぜ今のWebアプリはこの構造なのか」が分かると、AIが生成するコードの意味が見えてくる。
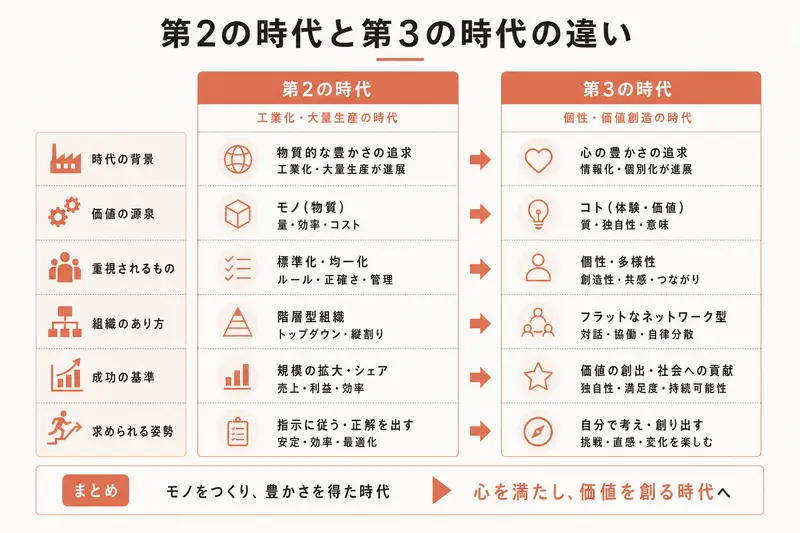
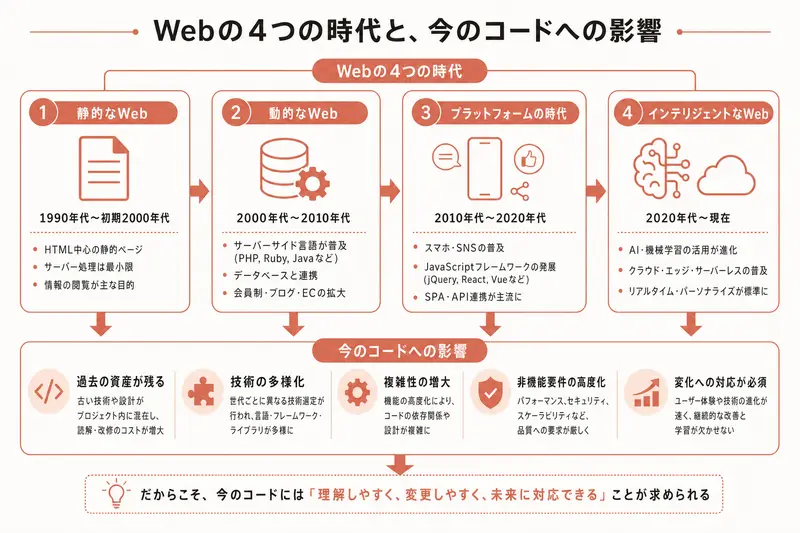
第1の時代: 紙のメニューだけのレストラン(静的ページ)
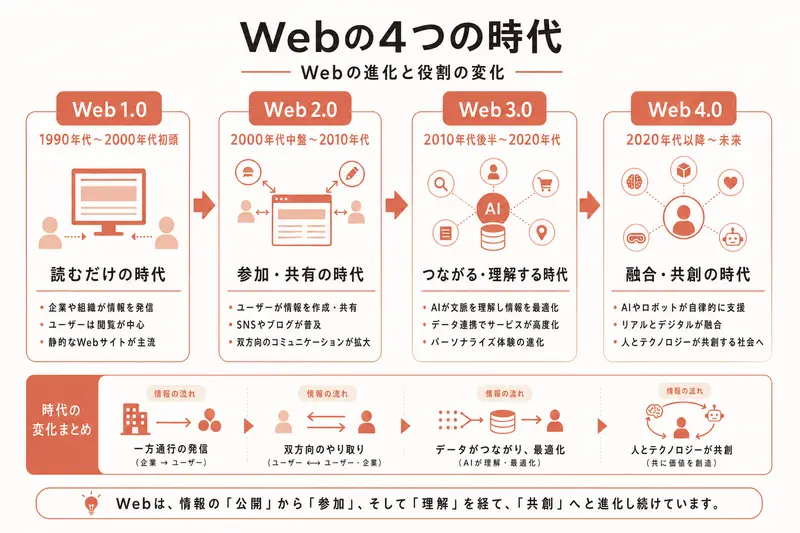
1990年代前半。Webが生まれたばかりの頃。この時代のWebサイトは、紙のチラシのようなものだった。
レストランで例えるなら「紙のメニューだけの店」だ。お客さん(ブラウザ)が来ると、あらかじめ印刷されたメニュー(HTMLファイル)を渡す。メニューの内容は固定で、誰が見ても同じ。注文を受けることもできないし、お客さんの好みに合わせてメニューを変えることもできない。
この時代のWebページは「静的ページ」と呼ばれる。静的とは「変化しない」という意味だ。HTMLファイルをサーバーに置いておくだけ。サーバーは、リクエストが来たらそのファイルをそのまま返す。キッチン(バックエンド)もほぼ不要。冷蔵庫(データベース)も不要。
当時のWebサイトは、大学の研究論文を共有するために作られた。文章と画像が並んでいるだけ。ログイン機能もない。検索機能もない。ショッピングカートもない。
今でも静的ページは使われている。会社紹介のページ、ブログの記事、ニュースサイトの一部は、基本的に静的ページだ。CursorやClaude Codeで「ランディングページを作って」と頼むと、この形に近いものが生成されることがある。
第2の時代: 注文を受けてから作るレストラン(動的ページ)
1990年代後半から2000年代前半。Webが商業利用され始め、Amazon、楽天、Yahoo!ショッピングなどが登場した時代。
レストランに例えると「注文を受けてから料理を作る店」になった。お客さんが「鶏肉のパスタをください」とリクエストすると、キッチン(バックエンド)が冷蔵庫(データベース)から材料を取り出し、その場で料理を作って、完成した皿をお客さんに出す。
これが「動的ページ」だ。動的とは「リクエストに応じて変化する」という意味。同じURLにアクセスしても、ログインしている人によって表示内容が変わる。商品の検索結果も、入力したキーワードによって変わる。
この時代に、第2回で解説した3層構造が確立された。フロントエンド、バックエンド、データベースの3つが連携してページを作る。
ただし、この時代の仕組みには1つの特徴があった。ページを表示するたびに、サーバーがHTMLをゼロから組み立てて返していたこと。ボタンを1つ押すだけでも、サーバーがページ全体を作り直して、ブラウザに送り返していた。
レストランに例えるなら、お客さんがドリンクを追加注文するたびに、テーブルの上を全部片付けて、料理もドリンクも最初から作り直して出すようなものだ。非効率だが、当時はこれが当たり前だった。
第3の時代: キッチンとホールが完全分業(API+SPA)
2010年代。スマートフォンが普及し、Webアプリの使い心地がネイティブアプリ(スマホにインストールするアプリ)に近づくことが求められた時代。
この時代に2つの重要な概念が広まった。REST API(レスト・エーピーアイ)とSPA(エス・ピー・エー)だ。
REST APIとは何か
API(エーピーアイ)とは、プログラム同士がデータをやりとりするための窓口のことだ。レストランに例えるなら、キッチンに設けられた「受け渡し口」にあたる。
それまでの時代は、キッチン(バックエンド)が料理を作るだけでなく、お皿への盛り付け(HTMLの組み立て)まで担当していた。完成した料理(HTMLページ)をそのままお客さんに渡していた。
REST APIの時代になると、キッチンの役割が変わる。キッチンは「材料を加工して渡す」だけになった。盛り付けはホール(フロントエンド)がやる。キッチンが渡すのは料理そのものではなく、調理済みの材料 — つまりデータだけだ。
このデータのやりとりに使われる形式がJSON(ジェイソン)だ。第1回のレスポンスの話で少し触れた。JSONとは、データを人間にも機械にも読める形で書いたテキストのことだ。たとえば、ユーザー情報なら次のような形になる。
{"name": "田中太郎", "email": "tanaka@example.com", "plan": "business"}
HTMLページ全体を返す代わりに、こういうデータだけを返す。これがREST APIの基本的な考え方だ。
RESTというのは、このデータの受け渡し方に関するルール(設計の約束事)の名前だ。第1回で解説したHTTPメソッド — GET(見せて)、POST(送る)、PUT(書き換えて)、DELETE(消して)— を使って、データの操作を表現する。
SPAとは何か
SPA(Single Page Application=シングルページアプリケーション)とは、ページを移動しても画面全体を読み込み直さないWebアプリのことだ。
第2の時代では、リンクを押すたびにブラウザが新しいページをサーバーに要求し、画面全体が真っ白になってから新しいページが表示されていた。
SPAでは、最初に1回だけページを読み込む。その後は、必要なデータだけをAPI経由で取得して、画面の一部だけを書き換える。GmailやGoogleマップを使ったことがあれば、あの「ページ移動してもチラつかない」感覚がSPAだ。
レストランに例えると、こうなる。第2の時代は「新しい注文のたびにテーブルを片付けて、全部出し直す」だった。SPAの時代は「デザートを追加注文したら、デザートだけがテーブルに届く。他の料理はそのまま」だ。
この分業体制により、フロントエンドとバックエンドが完全に分離した。バックエンドはAPIを通じてデータを返すだけ。フロントエンドは、受け取ったデータを使って画面を組み立てる。お互いのコードに触れる必要がない。
React(リアクト)、Vue.js(ビュー・ジェイエス)、Angular(アンギュラー)といったフロントエンドのツールが登場したのも、この時代だ。CursorやClaude Codeが生成するコードに「React」の名前が出てくるのは、この流れの延長線上にある。
第4の時代: 効率化されたオペレーション(フルスタックフレームワーク)
2020年代。現在進行形の時代。
第3の時代のSPA+APIの構成は便利だったが、新しい問題も生まれた。フロントエンドとバックエンドが完全に分かれたことで、管理するコードが2倍になった。フロントエンドのプロジェクトとバックエンドのプロジェクトを別々に動かす必要があった。
また、SPAには「最初の表示が遅い」という弱点があった。ブラウザが最初にJavaScript(ジャバスクリプト: ブラウザ上で動くプログラミング言語)の大きなファイルを読み込んで、そこから画面を組み立てるため、最初のページ表示に時間がかかる。Googleの検索にも不利だった。
そこで登場したのがフルスタックフレームワークだ。代表格がNext.js(ネクストジェイエス)。CursorやClaude Codeでアプリを作ると、Next.jsが使われることが多い。
レストランに例えると「キッチンとホールの連携を効率化するオペレーションシステム」にあたる。キッチンとホールの分業は維持しつつ、両方を1つのシステムで管理する。注文の種類によって「この料理はキッチンで盛り付けまでやったほうが早い」「この料理はホールでお客さんの目の前で仕上げたほうがいい」と、臨機応変に対応する。
技術的に言うと、Next.jsはサーバーサイドレンダリング(SSR: サーバー側でHTMLを組み立ててから返す方式)とクライアントサイドレンダリング(CSR: ブラウザ側でHTMLを組み立てる方式)を、ページや部品ごとに使い分けられる。最初の表示はサーバーで作って素早く返し、その後の操作はブラウザ側で処理する。両方の良いところを取った仕組みだ。
これが、CursorやClaude Codeが生成するコードに「Server Component(サーバーコンポーネント)」と「Client Component(クライアントコンポーネント)」という2種類が出てくる理由だ。第2回で触れたように、page.tsxやlayout.tsxがServer Component(サーバー側で動く部品)、'use client' と書かれたファイルがClient Component(ブラウザ側で動く部品)にあたる。
4つの時代が、AIが書くコードに残っている
ここまで読んで「歴史は分かったけど、自分のバイブコーディングに何の関係があるのか」と思ったかもしれない。実は、大いに関係がある。
CursorやClaude Codeが生成するコードには、4つの時代すべての要素が混在している。なお、そもそもClaude Codeがどんなツールなのかを先に押さえたい方は、Claude Codeの読み方・意味・できることが5分で読める。
静的ページの技術 → HTMLとCSS(見た目を作る言語)は今でもWebの基礎だ。Tailwind CSS(テイルウィンドCSS)という名前が出てくるのは、CSSを効率よく書くためのツール。
動的ページの技術 → データベース(Supabase)を使ってデータを保存・取得する仕組み。第2回で解説した3層構造。
API+SPAの技術 → app/api/ フォルダにあるREST APIのコード。Reactを使ったフロントエンドの部品。JSONでデータをやりとりする仕組み。
フルスタックの技術 → Next.jsのServer ComponentとClient Component。ページによってサーバーで処理するかブラウザで処理するかを使い分ける仕組み。
4つの時代の技術が層のように重なっている。だからファイルが多い。だから構造が複雑に見える。でも、それぞれの技術が生まれた背景を知っていれば「このファイルは第3の時代のAPIの仕組みだな」「これは第4の時代のServer Componentだな」と見当がつく。
AIにエラーを報告するときも「APIからのレスポンスが空です」「Server Componentでデータベースへの接続が失敗しています」と具体的に伝えられる。歴史の知識が、そのまま問題解決のボキャブラリーになる。
よくある不安と答え
4つの時代を全部理解しないといけないのか?
いけなくはない。バイブコーディングで日常的に意識するのは第3と第4の時代だ。ただ「静的ページ」と「動的ページ」の違いが分かるだけでも、AIが生成するコードの見え方は変わる。全部を深く理解する必要はない。
REST APIを自分で書けるようになる必要はあるか?
ない。CursorやClaude Codeが書いてくれる。あなたが知っておく必要があるのは「APIとはデータの受け渡し口である」「JSONという形式でデータがやりとりされる」という2点だけだ。
SPAとSSRの違いが難しい。どちらが良いのか?
どちらが良いかを判断する必要はない。Next.jsが両方を組み合わせてくれる。CursorやClaude Codeも、状況に応じてどちらを使うかを自動で判断する。あなたが覚えておくのは「Server Component=サーバー側で処理」「Client Component=ブラウザ側で処理」という区別だけで十分だ。
なぜ古い技術がまだ使われているのか?
Webは「後方互換性」を大事にしている。後方互換性とは「新しい技術を導入しても、古い技術で作ったものが壊れないようにする」という原則だ。1990年代に作られたHTMLのページは、2026年の今でもブラウザで表示できる。だから古い技術が消えずに残っていて、新しい技術と一緒に使われている。
まとめ
Webは4つの時代を経て、今の形になった。紙のメニューだけの静的ページ → 注文を受けて作る動的ページ → キッチンとホールが完全分業するAPI+SPA → 両者を効率的に統合するフルスタックフレームワーク。CursorやClaude Codeが生成するコードには、この4つの時代すべての技術が層のように重なっている。「なぜファイルがこんなに多いのか」「なぜこの構造なのか」は、歴史を知ることで答えが見える。エラーに遭遇したとき「これはAPIの問題か」「Server Componentの問題か」と切り分けるための地図が、あなたの中にできたはずだ。
次回は第4回 URLの読み方 — アドレスバーの文字列を分解してみる。ブラウザのアドレスバーに表示されるあの文字列が何を意味しているのか、Next.jsがURLをどう処理しているのかを解説する。
歴史で全体像を掴んだら、次は手を動かす番だ。無料のはじめてのClaude Codeプレイブックに、最初のアプリを作るまでの手順を画面つきでまとめている。
参考リファレンス
- MDN Web Docs「Webの進化」— Webの歴史と技術の変遷を扱った公式リファレンス
- 前回: 第2回 フロントエンド・バックエンド・データベース — 3層構造を理解する
- 次回: 第4回 URLの読み方 — アドレスバーの文字列を分解してみる
- バイブコーディング入門 カリキュラム(/vibe-coding)



