
冒頭:Playwrightで詰まった全ての人へ
「競合のこの記事、Claude Codeに読ませて要約してもらいたいだけなのに」。そう思ってスクレイピング(= Webページから情報を自動で取ってくる作業)に手を出した瞬間、多くの人はこう気づく。
- Playwright / Puppeteer(= ブラウザを裏で動かす自動化ツール)の環境構築が重い
- サイトごとにHTMLの構造が違うのでセレクタ(= 取りたい部分の住所指定)が壊れる
- JavaScriptで後から描画されるページは単純なfetchでは取れない
あるニッチメディアをひとりで運営している方は、この全てを捨てて 「1行のcurl」 に置き換えた。使ったのは Jina Reader API というサービスと、Claude Code。結果、競合リサーチにかけていた週10時間が週1時間になったという。
本記事では、そのパイプライン(= 処理の流れ)を6つのレイヤーに分けて解説する。非エンジニアの方でも、最後まで読めば「自分のメディアにも組み込めそう」と思えるはずだ。
FIGURE:concept: 6レイヤー全体像
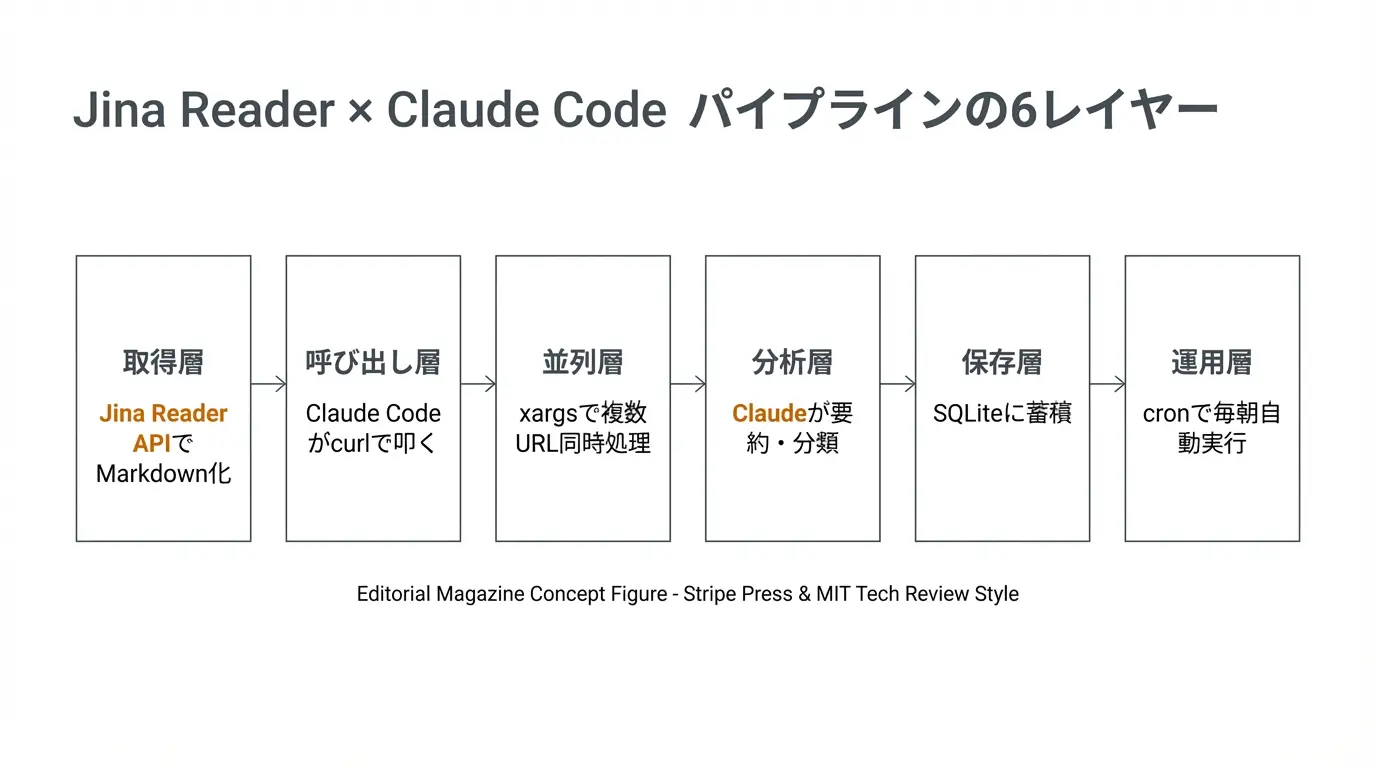
全体像はこうなっている。
- 取得層: Jina Reader API が任意のURLをMarkdown化
- 呼び出し層: Claude Code が curl または fetch で叩く
- 並列層: 複数URLを同時に処理する小さなシェルスクリプト
- 分析層: 返ってきたMarkdownをClaudeが読んで要約・分類
- 保存層: 結果をローカルのファイル or SQLite(= 軽量なデータベース。Excelに近い感覚)に保存
- 運用層: cron(= 定時実行の仕組み。目覚まし時計のようなもの)で毎朝自動実行
ひとつずつ見ていこう。
レイヤー1: 取得層 — Jina Reader というズルい発明
Jina Reader API は、以下のURLにGETリクエスト(= Webページを見に行く動作)を送るだけで動く。
https://r.jina.ai/https://claudelab.jp
たったこれだけで、JavaScriptで描画された後の綺麗なMarkdownが返ってくる。ヘッドレスブラウザ(= 画面を表示しない裏方ブラウザ)は一切不要。
読めなくても大丈夫。要点はこうです:「取りたいページのURLの前に https://r.jina.ai/ を付けるだけで、そのページがAIの読みやすい形で返ってくる」。それだけ。
料金は無料枠があり、本格運用でも 月$9(約1,350円)から。ひとりメディアなら有料プランでも十分元が取れる。
レイヤー2: 呼び出し層 — Claude Codeから1行で叩く
Claude Code(= ターミナルで動くAIアシスタント)に、こうお願いするだけで済む。
curl https://r.jina.ai/https://claudelab.jp > article.md
読めなくても大丈夫。要点はこうです:「Claude Codeに『このURLをJina Reader経由で取って、article.md に保存して』と日本語で頼めば、上のコマンドを自動生成して実行してくれる」。
PythonもNode.jsも不要。Macに最初から入っている curl(= ファイルを取ってくる標準ツール)だけで完結する。
この呼び出しを人間が打つのではなく、Claude自身に定時で実行させる仕組みが claude -p(= 対話画面を開かないヘッドレスモード)だ。詳しくはclaude -p とは|ヘッドレスモードの解説記事にまとめている。
レイヤー3: 並列層 — 100記事を3分で取る
1記事ずつ取っていては遅い。そこで並列実行(= 複数を同時に走らせる)する。xargs というツール(= 並べたリストを順に処理する係)を使えば、10行未満のスクリプトで数十URLを同時に取得できる。
比喩で言うと:レジが1台しかないスーパーから、レジ10台のスーパーに変わるイメージ。待ち行列が一気に消える。
実際の運営者は「朝の6時に競合30サイトのRSS(= 更新通知の仕組み)から新着URLを集め、Jina Readerで並列取得、Claudeで要約、業務日報のようにMarkdownにまとめる」ところまでを自動化している。所要時間は5分以内。
FIGURE:flow: 毎朝の自動実行フロー
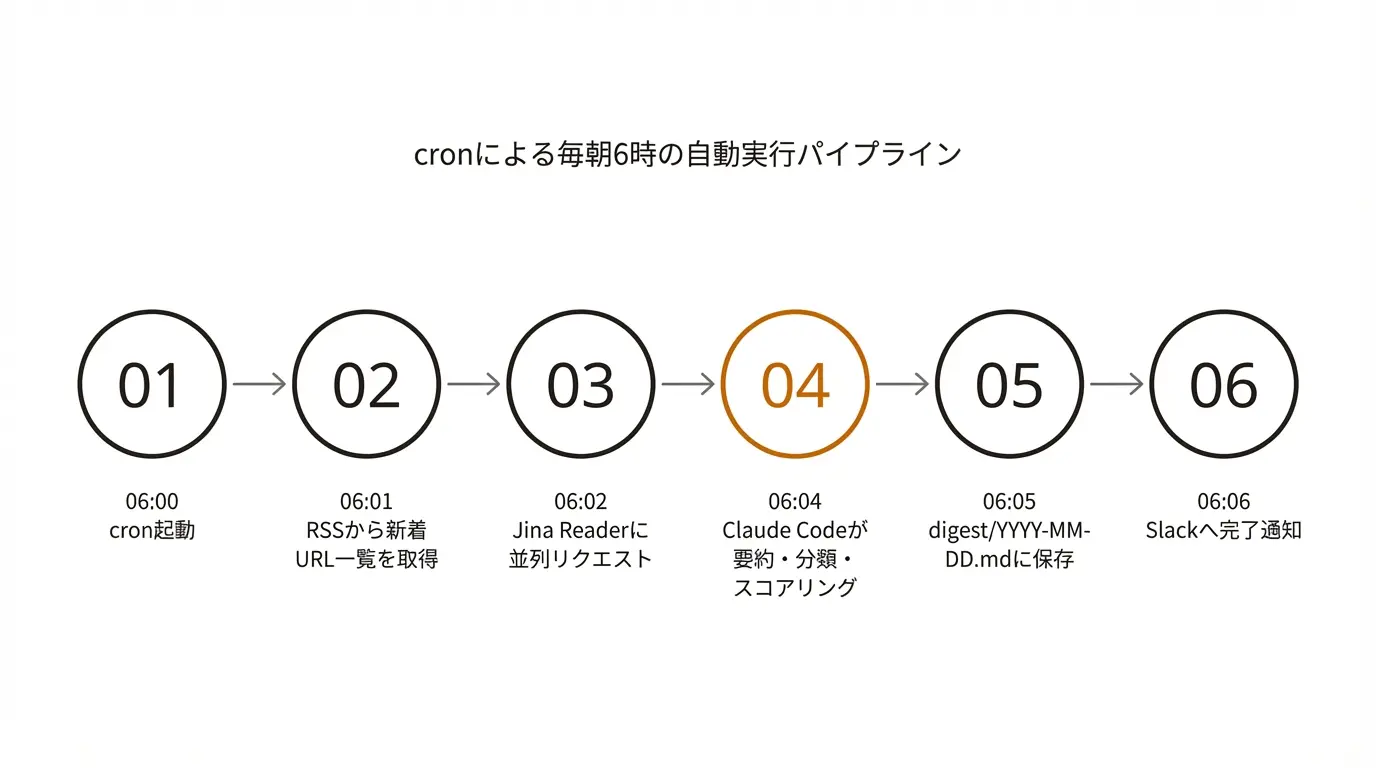
時系列にするとこうなる。
- 06:00 cron が起動(目覚まし時計が鳴る)
- 06:01 RSSから新着URL一覧を取得
- 06:02 Jina Readerに並列リクエスト
- 06:04 Claude Codeが各記事を要約・分類・スコアリング
- 06:05 結果を
digest/YYYY-MM-DD.mdに保存 - 06:06 完了通知をSlackへ
この流れは一度組んでしまえば、あとは勝手に動き続ける。「ひとり編集部」に最も足りないのは時間であり、Jina Readerはその時間を取り戻す道具だ。完了通知の設計(成功も必ず通知して「沈黙」を殺す考え方)はDiscord Webhook通知の可視化パターンが詳しい。また、cronを自分のMacで回したくない場合は、Claude Code Routinesでクラウド側の定時実行に置き換えられる。
レイヤー4: 分析層 — Claudeが読めば終わり
Markdownになったコンテンツは、Claude Codeにとって「最も得意な入力形式」だ。HTMLタグのノイズがなく、見出し・本文・リストが整理されているので、要約・分類・競合比較の精度が跳ね上がる。
運営者はこう使っている:
- 「この30記事のうち、自分のメディアでまだ扱っていないテーマを3つ挙げて」
- 「各記事のフックの書き出し方だけ抽出して一覧にして」
- 「競合が強調しているキーワード上位20個を出して」
Playwrightで消耗していた時間が、全て「問いを立てる時間」に変わる。なお、取得したページが日本語でも英語でも、Claudeは同じ精度で読める。海外競合の観測をそのまま日本語メディア運営の武器にできるのは、この構成の隠れた強みだ。
レイヤー5: 保存層 — 軽くていいならSQLiteで十分
取得したMarkdownと要約結果は、SQLite(= ファイル1個で完結するミニDB)に入れておけば検索・再利用が楽になる。MySQLやPostgreSQLのような本格DBは不要。
比喩で言うと:Excelファイル1個をデータベースとして使う感覚。バックアップも「そのファイルをコピーするだけ」。
取得結果だけでなく、実行コストや成功・失敗の履歴ごとSQLiteに蓄積する設計は、エージェント実行をSQLiteで全部記録するで深掘りしている。
レイヤー6: 運用層 — エラーハンドリングとキャッシュ
本番運用で必ずぶつかる2つの壁がある。
- 失敗するURLがある: タイムアウトや403エラー
- 同じページを何度も取ってしまう: 料金と時間の無駄
解決策はシンプルで、失敗URLは failed.txt に退避して翌日再試行、成功したURLはハッシュをキーにローカルキャッシュ(= 一度取ったものを覚えておく仕組み)に保存する。どちらもシェルスクリプト数行で済む定型パターンで、記事末尾で配布している雛形zipに組み込み済みだ。
FIGURE:comparison: Playwright運用 vs Jina Reader運用

| 観点 | Playwright | Jina Reader |
|---|---|---|
| 環境構築 | Node + ブラウザバイナリ | curl だけ |
| セレクタ保守 | サイトごとに必要 | 不要(Markdownで返る) |
| JS描画 | 対応(重い) | 対応(軽い) |
| 並列実行 | メモリを食う | HTTPなので軽い |
| 料金 | サーバー代 | 月$9〜 |
| 学習コスト | 高 | ほぼゼロ |
個人運営者にとって、この差は決定的だ。
エンジニアじゃない方へのメッセージ
ここまで読んで「やっぱり難しそう」と感じた方へ。
実は、この仕組みで一番大事なのは 「Claude Codeに日本語で頼むこと」 だけだ。コードを書く必要はない。
「Jina Reader を使って、このURLリストの記事を全部取ってきて、要約してMarkdownにまとめて」。この一文をClaude Codeに投げれば、本記事で紹介した仕組みをその場で組み立ててくれる。あなたがやるのは、結果を読んで「いいね」「ここ直して」と会話することだけ。
技術的ハードルに怯んで個人メディアを諦めていた方にとって、Jina ReaderとClaude Codeの組み合わせは 「最も低い階段」 という選択肢になる。
雛形一式を無料配布している
本記事の「取得 → AI処理 → 保存 → 通知」の流れをコピペで動く状態にした雛形セットを、Claude Code ヘッドレスパイプライン構築キット(zip)として無料配布している。解凍して、あなたのメディアテーマに合わせてURLリストを書き換えるだけで動き出す。



